
Modern IT environments are no longer simple or predictable. If you manage applications today, you are dealing with cloud platforms, containers, microservices, APIs, CI/CD pipelines, third-party services, and users spread across regions and devices. Each of these components generates logs, metrics, traces, alerts, and events, often at a massive scale. The challenge is no longer getting data; the real problem is understanding which signals actually matter and acting on them fast enough to prevent downtime. This is exactly the problem AIOps is designed to solve.
Instead of forcing you to manually interpret thousands of alerts or stare at dashboards hoping to spot issues early, AIOps uses machine learning to continuously analyze operational data. It helps you detect anomalies, correlate related events, identify root causes, and automate responses before small issues turn into major outages. If system reliability, performance, and operational efficiency matter to you, AIOps is not a buzzword; it is a practical operational capability.
What Is AIOps?
AIOps, short for Artificial Intelligence for IT operations, is the application of machine learning, analytics, and automation to IT operations data. Its purpose is to help you run complex systems more reliably by turning raw telemetry into actionable insights.
Traditional IT operations rely heavily on static rules and thresholds. For example, you might trigger an alert if CPU usage exceeds a fixed percentage. AIOps goes beyond this by learning normal behavior across your environment and detecting anomalous patterns in real time. Instead of asking “Did this metric cross a threshold?”, AIOps asks “Is this behavior unusual given historical patterns, dependencies, and current conditions?”
At a practical level, AIOps helps you:
- Detect incidents earlier
- Reduce alert noise
- Identify root causes faster
- Automate repetitive remediation tasks
- Improve long-term system reliability
How AIOps Works Step By Step
To understand AIOps properly, you need to examine the workflow from raw data to action.
Step 1: Data Collection From Across Your Environment
AIOps platforms ingest data from multiple sources, including:
- Application logs
- Infrastructure and cloud metrics
- Network events
- Distributed traces
- Configuration changes
- Historical incidents and tickets
This data is normalized so different formats, timestamps, and sources can be analyzed together.
Step 2: Baseline Learning and Anomaly Detection
Machine learning models analyze historical data to understand what “normal” looks like for each system, service, and metric. Once baselines are established, the system continuously watches for deviations such as:
- Unusual latency spikes
- Error rate increases
- Resource exhaustion patterns
- Behavioral changes after deployments
These anomalies are detected even if no predefined rule exists.
Step 3: Event Correlation and Context Building
Instead of treating each alert separately, AIOps correlates related signals across systems. Multiple alerts triggered by the same underlying issue are grouped into a single incident. Dependency maps help determine which component is most likely the root cause rather than a downstream symptom.
Step 4: Root Cause Analysis and Prioritization
AIOps evaluates impact, historical patterns, and system dependencies to suggest probable root causes. Incidents are prioritized based on severity and business impact, so you know what to fix first.
Step 5: Remediation and Automation
Depending on configuration, AIOps can:
- Recommend remediation steps
- Trigger runbooks
- Automatically restart services
- Scale infrastructure
- Roll back faulty deployments
Automation can be human-approved or fully autonomous, depending on risk tolerance.
Core Components Of An AIOps Platform
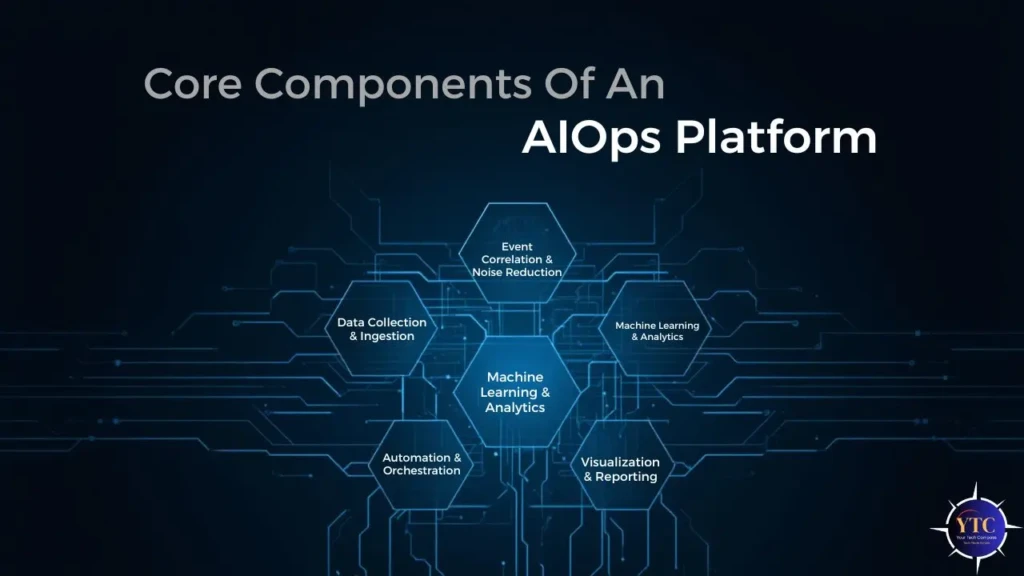
A functional AIOps platform typically includes the following components:
- Data Ingestion and Storage: Handles high-volume telemetry and long-term historical data.
- Machine Learning and Analytics Engine: Drives anomaly detection, correlation, and prediction.
- Topology and Dependency Mapping: Visualizes relationships between services, infrastructure, and applications.
- Alert Management System: Reduces alert fatigue by consolidating and prioritizing incidents.
- Automation and Orchestration Layer: Executes remediation actions through workflows and runbooks.
Practical AIOps Use Cases
AIOps delivers value when applied to real operational problems.
- Incident Detection and Faster Resolution: AIOps detects issues earlier and provides context, reducing mean time to resolution.
- Predictive Maintenance: By identifying patterns that precede failures, you can prevent outages.
- Performance and Reliability Optimization: AIOps identifies bottlenecks and inefficiencies that affect user experience.
- Alert Noise Reduction: Instead of hundreds of alerts, you deal with a few meaningful incidents.
- Capacity and Cost Management: AIOps helps forecast resource needs and reduce waste in cloud environments.
AIOps Vs Traditional IT Operations
Area | AIOps | Traditional IT Ops |
Monitoring | Behavior-based | Threshold-based |
Alert Volume | Correlated and reduced | High and noisy |
Root Cause Analysis | Automated, data-driven | Manual and slow |
Scalability | Built for complex systems | Struggles at scale |
Automation | Native and adaptive | Limited scripts |
Benefits You Can Expect From AIOps
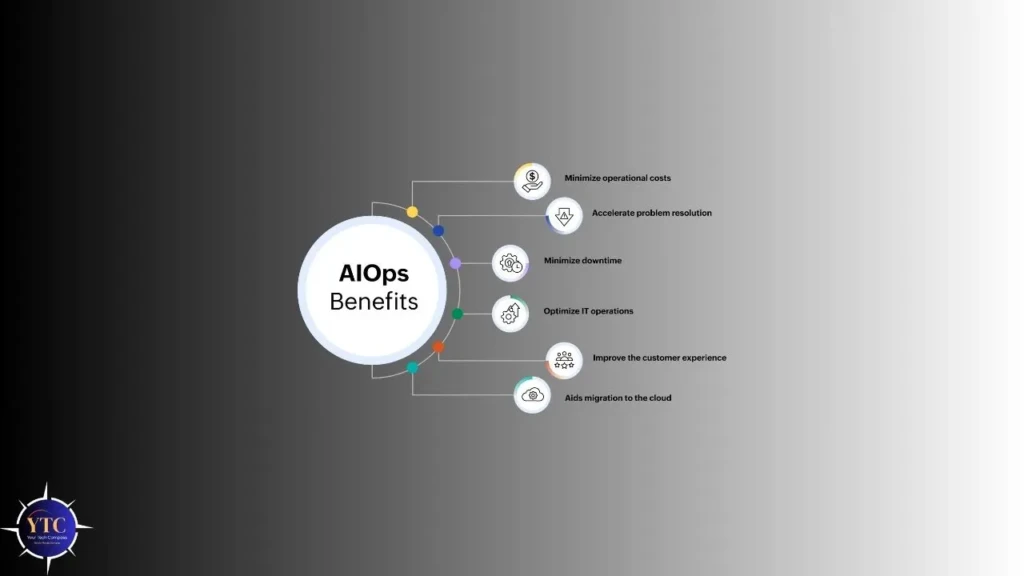
When implemented correctly, AIOps delivers measurable operational improvements:
- Faster incident detection and resolution
- Fewer false alarms and alert fatigue
- Improved system uptime and stability
- Better use of engineering time
- Stronger collaboration between DevOps, SRE, and IT teams
These benefits compound as models learn from new data and incidents.
Limitations and Risks You Should Understand
AIOps is not magic, and misuse can create problems.
Poor telemetry quality leads to poor insights. Over-automation without safeguards can cause cascading failures. Models require tuning, validation, and trust-building within teams. Costs and integration complexity must also be justified by real operational gains.
Knowing these limitations helps you adopt AIOps realistically rather than blindly.
How To Implement AIOps Successfully
A practical implementation follows a clear progression:
- Audit existing telemetry and data gaps
- Start with a high-impact pilot service
- Build accurate dependency maps
- Tune anomaly detection models
- Introduce automation gradually with approvals
- Measure outcomes such as MTTR reduction and alert volume
Scaling AIOps without proving value first usually leads to failure.
Who Should Use AIOps?
AIOps is ideal if you manage:
- Distributed or cloud-native systems
- High alert volumes
- Frequent incidents
- Rapidly scaling infrastructure
As environments grow more complex, AIOps becomes less optional and more foundational.
Conclusion

AIOps represents a shift in how you operate modern systems. Instead of reacting to problems after users are already affected, you can detect issues earlier, understand them faster, and resolve them more intelligently. By combining machine learning, automation, and operational data, AIOps helps you regain control in environments that are otherwise too complex for manual oversight.
When adopted thoughtfully, AIOps does not replace human expertise; it amplifies it. The most successful teams treat AIOps as a decision-support and automation layer, not a blind authority. With clean data, clear goals, and disciplined rollout, AIOps becomes a powerful foundation for reliable, scalable, and efficient IT operations.
FAQs
No. Any team managing complex systems can benefit, regardless of size.
No. AIOps supports engineers by automating repetitive work and improving decision-making.
Initial improvements often appear within weeks, with deeper benefits over time.
No. Observability provides data; AIOps turns that data into insights and actions.
At Your Tech Compass, we publish detailed tech guides, reviews, and comparisons to help users choose the right devices and tools.


