Anthropic released Claude Opus 4.7 on April 16, 2026, and the timing tells you something important about where the AI competition stands right now. This release lands just six weeks after OpenAI shipped GPT-5.4, and Anthropic’s announcement was explicit: Opus 4.7 outperforms GPT-5.4 and Google’s Gemini 3.1 Pro on key benchmarks, including agentic coding, scaled tool use, agentic computer use, and financial analysis. That’s a meaningful competitive statement, and one backed by benchmark data rather than marketing copy. Importantly, though, Opus 4.7 is not Anthropic’s most powerful model. Claude Mythos Preview, announced through Project Glasswing earlier this month, sits above it. Mythos remains restricted to a small group of vetted enterprise partners for safety reasons, so Claude Opus 4.7 is the most capable Claude model you can access in full right now.
This guide covers everything you need to know about Claude Opus 4.7: what genuinely changed from 4.6, what the benchmarks mean for your specific work, how it stacks up against GPT-5.4, what it costs, and who this model is actually built for. Whether you’re a developer evaluating your API stack, an enterprise team assessing Anthropic’s latest for production workflows, or a professional who uses Claude daily and wants to know if anything changes for you, this is the complete, honest picture.
Before we get into it: this review is independent. No brand paid for coverage, and no score was negotiated. If you want to see exactly how we evaluate tools: what we test, how we score, and how we handle affiliate relationships, our Review Methodology has all of it.
What Is Claude Opus 4.7?
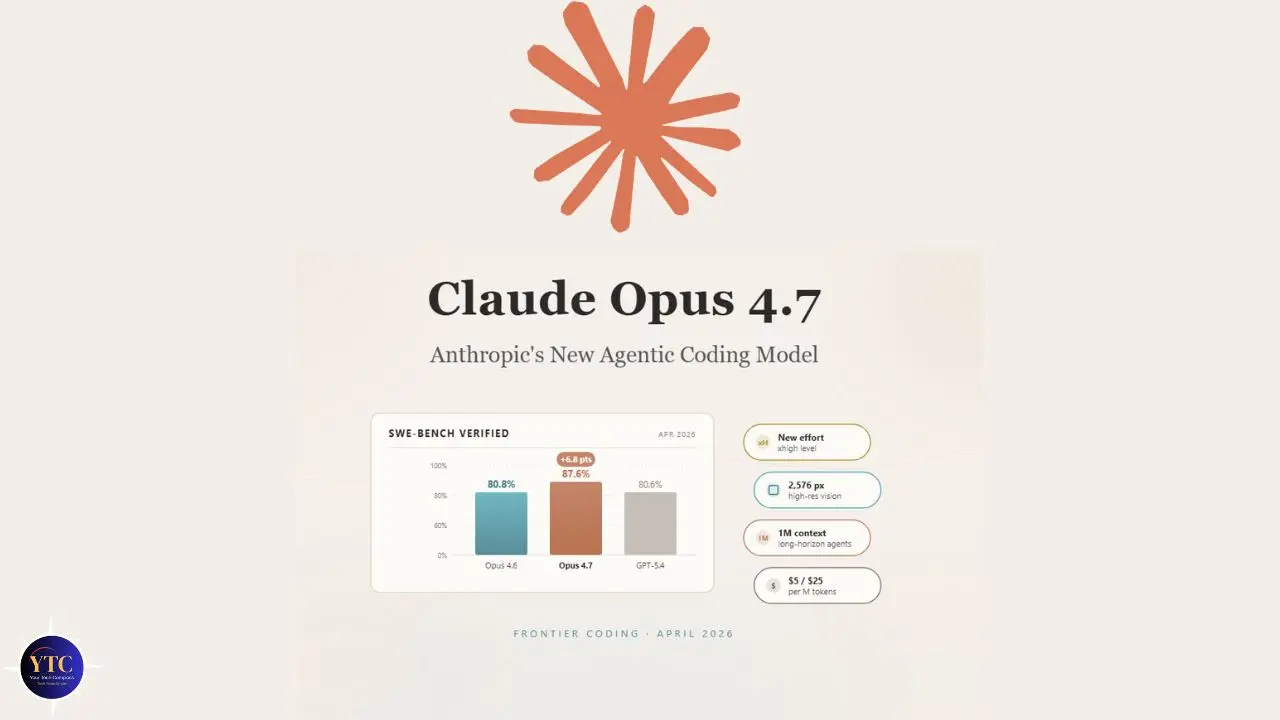
Claude Opus 4.7 is Anthropic’s most capable generally available frontier model, an update within the Claude 4 model family that builds directly on Claude Opus 4.6. Released on April 16, 2026, it maintains Anthropic’s roughly two-month release cadence: Opus 4.5 launched in November 2025, Opus 4.6 in February 2026, and Opus 4.7 in April 2026. This cadence matters because it tells you how to think about Opus 4.7: a targeted capability advance, not an architectural overhaul.
Anthropic positions Claude Opus 4.7 at the top of its publicly available model hierarchy, above Claude Sonnet 4.6 (the efficient mid-tier model) and Claude Haiku (the lightweight, fast-response tier). The only model that exceeds it is Claude Mythos Preview, which, as covered in our Claude Mythos explained guide, remains restricted to Project Glasswing partners due to its unprecedented cybersecurity capabilities and the safety protocols Anthropic is still developing around models at that capability level. For everyone else, Opus 4.7 is the ceiling.
Available immediately across all Claude products, claude.ai (Pro, Max, Team, and Enterprise plans), the Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Claude Opus 4.7 replaces Opus 4.6 as the default Opus model at the same pricing: $5 per million input tokens and $25 per million output tokens, with up to 90% cost savings through prompt caching and 50% savings with batch processing. Anthropic held pricing steady despite meaningful capability improvements, a deliberate choice that makes the upgrade compelling from a cost-efficiency perspective.
What’s New in Claude Opus 4.7

Advanced Software Engineering (The Headline Improvement)
The clearest single advance in Claude Opus 4.7 is in software engineering, and specifically in the hardest categories of coding work. Anthropic describes users as now being able to “hand off their hardest coding work; the kind that previously needed close supervision, to Opus 4.7 with confidence.” That’s a specific claim about a specific shift: not just better code generation, but reliable autonomous execution on complex, long-running tasks.
The benchmark numbers support it. On Hex’s internal 93-task coding benchmark, Claude Opus 4.7 lifted task resolution by 13% over Opus 4.6, including four tasks that neither Opus 4.6 nor Sonnet 4.6 could solve at all. That last detail matters: these aren’t tasks where 4.6 was close, and 4.7 is marginally better. These are problems that were genuinely outside the previous model’s capability ceiling.
Furthermore, Hex’s evaluation found that low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6, meaning you get higher capability at lower computational cost per task on much of your workload. Additionally, Claude Opus 4.7 introduces two new tools specifically for coding workflows.
The /ultrareview command in Claude Code runs a dedicated review session that simulates a senior human reviewer, flagging subtle design flaws and logic gaps that standard syntax checking doesn’t catch. And auto mode in Claude Code, which allows Claude to make autonomous decisions without constant permission prompts, has been extended to Max Plan users for the first time.
For developers building with Claude through Cursor or AI-integrated development environments, our Claude AI for Coding guide covers the specific prompting workflows and setup configurations that produce the best results with Opus-tier models.
Vision (3.75 Megapixels and 79.5% Visual Navigation)
Claude Opus 4.7’s second headline improvement is vision accuracy and resolution, and this one is concrete enough to give you specific numbers. Maximum image resolution has increased from 1,568 pixels on the long edge (approximately 1.15 megapixels) in Opus 4.6 to 2,576 pixels on the long edge (approximately 3.75 megapixels) in Opus 4.7. That is roughly 3x the visual processing capacity of the previous model.
What does that resolution increase actually mean in practice? Screenshots, dense technical diagrams, design mockups, financial charts, and scanned documents now come through at full fidelity, rather than the compressed, detail-losing analysis that lower-resolution processing produced. Consequently, visual analysis tasks that previously produced imprecise or partially incorrect results are handled with substantially greater accuracy.
The benchmark reflects this improvement directly. On visual navigation without tools (a measure of how accurately the model interprets and acts on visual content), Opus 4.7 at full resolution scores 79.5%, compared to 57.7% for Opus 4.6 on the same test. That’s a 21.8 percentage point improvement. For anyone whose work involves asking Claude to analyze charts, review design mockups, examine technical drawings, or process document images, this isn’t a marginal improvement; it’s a different category of reliability.
xhigh Reasoning Effort (Maximum Depth on Demand)
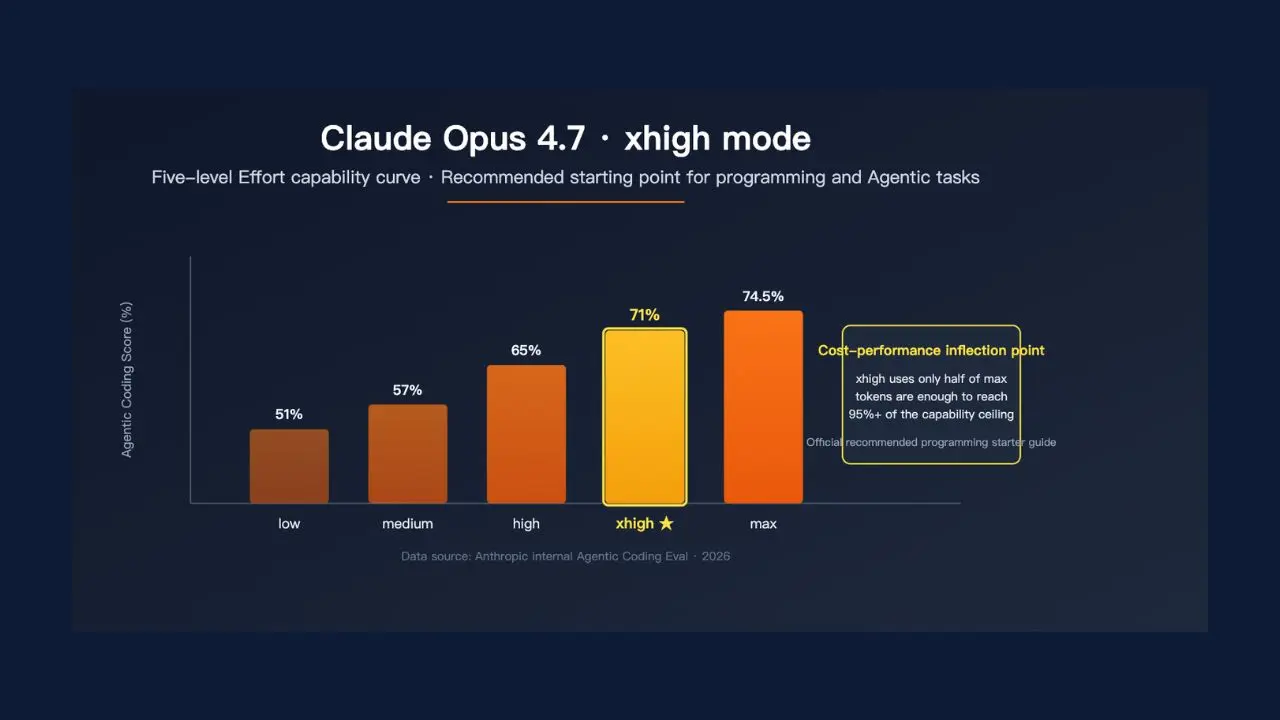
Claude Opus 4.7 introduces a new reasoning effort level called xhigh, which sits between the existing high and max settings and gives you finer control over the reasoning-depth versus response-speed tradeoff. Anthropic specifically recommends starting with xhigh for coding and agentic use cases, and Claude Code now defaults to xhigh for all plans.
What xhigh actually means: when you set Claude Opus 4.7 to xhigh effort, it invests significantly more computational depth in working through a problem before producing output. It considers more paths, checks its own reasoning more thoroughly, and produces more tool calls during agentic tasks.
The practical cost is higher latency and higher token consumption; at higher effort levels, Opus 4.7 “thinks more,” particularly on later turns in agentic settings, which produces more output tokens. The practical benefit is meaningfully better output quality on genuinely hard problems where a wrong answer has real consequences.
Therefore, for most everyday queries, such as standard writing, quick analysis, and routine coding, xhigh is overkill and adds unnecessary cost. However, for complex legal analysis, multi-step financial modeling, architectural decisions on large software systems, and research synthesis across contradictory sources, xhigh is specifically the right tool. The important addition here is that you now have a dedicated setting for that use case, rather than having to choose between high and max with no intermediate option.
Instruction-Following (More Literal, More Precise)
One of the less-headlined but practically significant improvements in Opus 4.7 is more literal instruction-following. Anthropic explicitly describes it: the model will no longer silently generalize an instruction from one item to another or infer requests you didn’t make. Where Opus 4.6 sometimes interpreted instructions loosely and skipped steps, Opus 4.7 takes them precisely.
This is a genuine quality-of-life improvement for professional workflows, and it’s the kind of change that matters most to people who use Claude for structured, repeatable tasks with specific output requirements. The honest caveat Anthropic includes: some users may need to adjust prompts optimized for earlier models, since Opus 4.7 responds somewhat differently to certain input patterns, particularly at lower-effort levels. Additionally, response length now adapts to task complexity rather than defaulting to a fixed verbosity, and the model makes fewer tool calls by default, reserving them for situations where they’re genuinely necessary.
File System Memory (Persistent Context Across Sessions)
Claude Opus 4.7 is better at using file-system-based memory; it can remember important notes across long, multi-session work and use them to approach new tasks that consequently need less up-front context. Agents that write to and read from scratchpads or notes files across long sessions get noticeably more reliable behavior in 4.7. Multi-session work that previously lost context now holds it.
This improvement is particularly meaningful for enterprise users running long-horizon agentic workflows, multi-day projects involving complex document generation, extended research sessions, or ongoing software development tasks. Anthropic positions Opus 4.7 explicitly as a model that “sets the standard for enterprise workflows, carrying context across sessions to manage complex, multi-day projects end-to-end.”
Task Budgets (New Beta Feature for API Users)

For API developers, Opus 4.7 introduces task budgets in public beta, a new feature that gives the model a rough token target for an entire agentic loop (thinking, tool calls, tool results, and final output). The model sees a running countdown and uses it to prioritize work and wrap up gracefully as the budget runs out. This is particularly useful for production systems that need predictable cost bounds for agentic workflows without sacrificing output quality within budget.
New Tokenizer (Important Migration Note)
Opus 4.7 uses an updated tokenizer that improves how the model processes text and contributes to its performance improvements. The migration implication: the same input text may produce 1.0x to 1.35x more tokens compared to Opus 4.6, depending on content type.
Anthropic recommends updating the max_tokens parameter to provide additional headroom and adding compaction triggers. And, for most users, this is a non-issue. However, for high-volume API deployments with tight cost margins, plan for the token overhead before migrating.
Claude Opus 4.7 vs Claude Opus 4.6
Capability | Claude Opus 4.6 | Claude Opus 4.7 | Difference |
Max Image Resolution | 1.15 megapixels (1,568px) | 3.75 megapixels (2,576px) | ~3x increase |
Visual Navigation Score | 57.7% | 79.5% | +21.8pp |
Coding Benchmark (93-task) | Baseline | +13% resolution | +13% lift |
Reasoning Effort Levels | None / Low / Medium / High / Max | + xhigh (new) | Finer control |
Instruction-Following | Loose generalization | Precise and literal | Meaningful improvement |
File System Memory | Basic | Reliable across sessions | Significant improvement |
Context Window | 1M tokens | 1M tokens | Unchanged |
Pricing (API) | $5/$25 per MTok | $5/$25 per MTok | Unchanged |
Tokenizer | Previous | Updated | 1.0–1.35x input tokens |
The honest verdict on upgrading from 4.6: if you’re on a plan that already gives you Claude Opus access, the upgrade is immediate and at no additional cost; Opus 4.7 replaces 4.6 as the default. Therefore, if you’re deciding whether the Opus tier is worth paying for over Sonnet 4.6, the 4.7 improvements on vision and coding specifically strengthen the case for Opus for those use cases. Additionally, if you’re an API developer currently on Opus 4.6, plan for the tokenizer overhead before upgrading production systems.
Claude Opus 4.7 vs GPT-5.4

This is the comparison professionals are actively tracking. The benchmark race between Anthropic and OpenAI in April 2026 is the closest it has ever been, on directly comparable benchmarks, Opus 4.7 leads GPT-5.4 on only 7 of 11 measures. Neither model is a clean sweep.
Here’s where each leads:
Category | Claude Opus 4.7 | GPT-5.4 | Leader |
Agentic Coding | ✅ Leads on benchmark | Strong (~80% SWE-bench) | Opus 4.7 |
Computer Use (OSWorld) | Below human baseline | 75% (above human 72.4%) | GPT-5.4 |
Vision Accuracy | 79.5% visual navigation | Strong; no equivalent stat | Opus 4.7 |
Image Resolution | 3.75MP | Lower ceiling | Opus 4.7 |
Image Generation | ❌ Not available | ✅ Native DALL-E | GPT-5.4 |
Context Window | ✅ 1M tokens | 272K standard (2x surcharge above) | Opus 4.7 |
Financial/Legal Analysis (GDPval-AA) | ✅ State of the art | Strong (83% GDPval) | Opus 4.7 |
Terminal-Based Coding | 69.4% (Terminal-Bench 2.0) | 75.1% | GPT-5.4 |
Agentic Search | 79.3% | 89.3% | GPT-5.4 |
Long-Form Writing Quality | ✅ Historically stronger | Closing the gap | Opus 4.7 |
API Pricing | $5/$25 per MTok | $2.50/$15 per MTok | GPT-5.4 |
Coding
Opus 4.7 outperforms GPT-5.4 on agentic coding benchmarks and the hardest task categories; the 13% lift on Hex’s 93-task benchmark, plus four tasks that GPT-5.4 can’t solve, is concrete evidence. However, GPT-5.4 leads on terminal-based coding tasks (Terminal-Bench 2.0: 75.1% vs 69.4%) and agentic search.
The Practical Implication: For developers doing complex multi-step coding work inside IDE environments, Opus 4.7 has the edge. However, for raw terminal-based execution, GPT-5.4 leads.
Vision
Opus 4.7’s 79.5% visual navigation score and 3.75 MP resolution represent a meaningful advance in visual analysis. GPT-5.4 includes native DALL-E image generation, which Opus 4.7 does not. This is the clearest single distinction: if you need to analyze images with precision, Opus 4.7 is stronger; if you need to generate images, GPT-5.4 is your only option.
Context Window
Claude Opus 4.7’s 1M-token context window, priced at standard rates with no long-context surcharge, remains a decisive advantage over GPT-5.4’s 272K standard context (which charges 2x the standard context threshold). For tasks requiring analysis of very large codebases, book-length documents, or extensive legal and financial document sets, this difference is not marginal.
Computer Use
This is GPT-5.4’s clearest advantage. Its 75% OSWorld score, surpassing the human expert baseline of 72.4%, is a genuine differentiator for agentic tasks requiring desktop environment navigation. Opus 4.7’s computer-use capabilities are improving, but they don’t match GPT-5.4 on this specific benchmark.
For more context on how GPT-5.4 achieved that computer-use score and what it means for your workflow, our ChatGPT 5.4 explained guide provides a full breakdown.
Pricing

GPT-5.4 is meaningfully cheaper at the API level, $2.50/$15 per million tokens versus Claude Opus 4.7’s $5/$25. For high-volume production deployments, that pricing difference matters. For most professional users on fixed monthly plans, it’s a non-factor.
The Honest Summary
Claude Opus 4.7 is the stronger choice for agentic coding, financial and legal knowledge work, high-resolution image analysis, and large-context document work. GPT-5.4 is the stronger choice for computer use, agentic search, terminal-based coding, image generation, and API cost efficiency. Neither model is universally dominant; the right choice depends on which tasks dominate your workflow.
Pricing and Access
Plan | Cost | Opus 4.7 Access |
Claude Free | $0 | ❌ Sonnet 4.6 only |
Claude Pro | $20/month | ✅ Full Opus 4.7 access |
Claude Max | $100–$200/month | ✅ Full access + auto mode in Claude Code |
Claude for Teams | $25/user/month (3-user min) | ✅ Full access + shared Projects |
Claude Enterprise | Custom | ✅ Full access + security/compliance |
Anthropic API | $5/$25 per million tokens | ✅ Model ID: claude-opus-4-7 |
Amazon Bedrock | Platform rates | ✅ Available now |
Google Vertex AI | Platform rates | ✅ Available now |
Microsoft Foundry | Platform rates | ✅ Available now |
The honest access picture: Claude Opus 4.7 requires a minimum Claude Pro subscription at $20/month for access to claude.ai. Free users remain on Claude Sonnet 4.6. Consequently, API users should use the model ID claude-opus-4-7.
Pricing is held steady from Opus 4.6, with up to 90% savings via prompt caching. One important planning note for API and enterprise users: budget for the tokenizer change, which increases input token counts by 1.0x to 1.35x depending on content type. Additionally, auto mode in Claude Code is now available for Max plan subscribers for the first time, previously restricted to Teams, Enterprise, and API customers, making the Max plan more compelling for heavy Claude Code users.
Who Is Claude Opus 4.7 Built For?
Professional Developers Doing Complex, Long-Running Coding Work

The 13% benchmark lift, the four newly solvable tasks, and the /ultrareview command in Claude Code are specifically designed for developers who need an AI collaborator on genuinely hard engineering problems, the kind that previously needed close supervision. Therefore, if your work involves multi-file refactoring, complex debugging sessions, or autonomous coding tasks that run over extended periods, Opus 4.7 is a meaningful advance over 4.6. Our Claude AI for Coding guide covers the setup and prompting workflows that get the most out of Claude’s Opus-tier coding capabilities.
Professionals Who Regularly Analyze Visual Content
The 3.75MP resolution ceiling and 79.5% visual navigation score make Opus 4.7 the strongest Claude model for charts, technical diagrams, design mockups, financial data visualizations, and dense document images. Consequently, if image analysis is a regular part of your workflow, this is the clearest single reason to be on Opus rather than Sonnet.
Enterprise and Regulated Industry Users
Anthropic’s Constitutional AI approach, and specifically the cyber safeguards built directly into Opus 4.7, produce the behavioral reliability and epistemic honesty that regulated industries require. Opus 4.7 correctly reports when data is missing, rather than providing plausible but incorrect fallbacks (per Hex’s evaluation), and it resists dissonant-data traps. Therefore, for finance, legal, healthcare, and compliance-sensitive contexts, epistemic honesty is a meaningful practical advantage.
For a broader context on Anthropic’s safety philosophy and the Mythos announcement that directly shaped Opus 4.7’s safety architecture, our Claude AI explained guide covers the Constitutional AI foundation and how it shapes model behavior.
Users With Large-Context Document Analysis Needs
The 1M token context window, held at standard pricing with no surcharge, remains Claude Opus 4.7’s clearest single technical advantage over GPT-5.4 for anyone who needs to analyze full codebases, extensive legal document sets, book-length research, or comprehensive financial reports in a single session.
Researchers and Analysts On Genuinely Hard Reasoning Problems
The xhigh reasoning effort level is the right tool for problems where thoroughness justifies additional latency: complex mathematical modeling, multi-jurisdictional legal analysis, scientific research synthesis across contradictory sources, and architectural decisions with significant downstream consequences.
Who Should Look Elsewhere?

- Users whose primary need is desktop computer use and agentic web navigation (GPT-5.4’s 75% OSWorld score leads).
- People who need native image generation (GPT-5.4 with DALL-E).
- Persons whose workflows are well-served by Sonnet 4.6 at a lower cost. This is because not every use case requires Opus-tier performance or pricing.
For a full landscape view of where Opus 4.7 fits among all current frontier AI models, our AI Unboxed section covers the complete competitive picture.
FAQs
Claude Opus 4.7 is Anthropic’s most capable generally available AI model, released April 16, 2026. It’s a direct upgrade to Claude Opus 4.6 within the Claude 4 model family, featuring a 13% improvement in coding benchmark, 3x higher image resolution (3.75MP), a new xhigh reasoning effort level, a new /ultrareview command in Claude Code, and improved instruction-following. It outperforms GPT-5.4 and Gemini 3.1 Pro on agentic coding, financial analysis, and computer use benchmarks.
It leads on specific benchmarks, such as agentic coding, financial and legal knowledge work (GDPval-AA), and high-resolution image analysis, and trails others, including computer use (OSWorld: 75% GPT-5.4 vs below-human baseline for Opus 4.7), terminal-based coding, and agentic search. On directly comparable benchmarks, Opus 4.7 leads GPT-5.4 on 7 of 11 measures. Neither model is universally dominant; the right choice depends on your primary use cases.
On claude.ai, Opus 4.7 is available to Claude Pro ($20/month), Max ($100–$200/month), Team ($25/user/month), and Enterprise subscribers. Via the API, use the model ID claude-opus-4-7. It’s also available through Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Pricing remains steady at $5 per million input tokens and $25 per million output tokens, as in Opus 4.6.
xhigh is a new reasoning effort level in Opus 4.7 that sits between the existing high and max settings. It gives the model more computational depth to work through problems before responding, producing higher-quality output on genuinely hard tasks at the cost of higher latency and more output tokens. Anthropic recommends xhigh for coding and agentic use cases. Claude Code defaults to xhigh for all plans.
Final Thoughts

Claude Opus 4.7 is Anthropic’s strongest publicly available model, and the benchmark evidence supports that description rather than just restating marketing copy. A 13% coding benchmark lift with four newly solvable tasks, a vision resolution jump from 1.15MP to 3.75MP, producing a 21.8 percentage point improvement in visual navigation accuracy, a new xhigh reasoning effort level for maximum-depth problem-solving, and more precise literal instruction-following combine to make Opus 4.7 a meaningfully better tool than 4.6 across the domains that matter most for professional use. The fact that pricing held steady at $5/$25 per million tokens makes the upgrade straightforward for current Opus users.
The competitive picture with GPT-5.4 is the closest it has ever been. Anthropic’s 7-of-11 benchmark lead is real but not dominant, and GPT-5.4 holds clear advantages on computer use, agentic search, image generation, and API cost efficiency. What Opus 4.7 establishes is a model that is the clear first choice for agentic coding, large-context document analysis, high-resolution image understanding, and the professional knowledge work categories (finance, legal, and research) where epistemic honesty and output reliability are not optional features. For the users that model is built for, Opus 4.7 delivers on the claims.
The frontier is moving faster than most coverage captures, and knowing which model is actually better for your specific work matters more than knowing which one got the bigger headline. Get the honest, practical breakdown of every major AI release at YourTechCompass.com, where we track what actually changes so you don’t have to track everything.