
OpenAI released GPT-5.4 on March 5, 2026, and if you’ve been watching AI releases long enough, you know the pattern: every model drop arrives with breathless coverage that makes it sound like everything just changed overnight. The honest picture with ChatGPT 5.4 is more interesting than the hype and more useful than the dismissals. This isn’t a new model generation. It’s OpenAI’s most capable and efficient frontier model to date within the GPT-5 family, a release that fuses the reasoning advances from GPT-5.2, the coding capabilities of GPT-5.3-Codex, and native computer use into a single unified model. The result is genuinely significant for professionals and developers, and it matters much less if you use ChatGPT to draft quick emails or answer simple questions.
This guide covers everything you actually need to know about ChatGPT 5.4: what’s new, what the benchmarks mean in real-world terms, how it compares to its predecessors and to Claude, who can access it, what it costs, and the straight verdict on whether it changes anything for you specifically. No padding, no hype. Just the complete picture.
Before we get into it: this review is independent. No brand paid for coverage, and no score was negotiated. If you want to see exactly how we evaluate tools: what we test, how we score, and how we handle affiliate relationships, our Review Methodology has all of it.
What Is ChatGPT 5.4?
ChatGPT 5.4, officially named GPT-5.4, is a point release within OpenAI’s GPT-5 model family, released on March 5, 2026. Understanding what “point release” means is important before evaluating it: GPT-5 (released August 2025) represented a major architectural advance; GPT-5.4 is OpenAI iterating on that foundation with targeted capability improvements rather than building a new architecture from scratch. That framing matters because it sets the right expectations. You’re not looking at a new AI era; you’re looking at the best version of an already-strong model family.
What makes GPT-5.4 genuinely noteworthy is what it unified. OpenAI built it as their first mainline reasoning model, incorporating the frontier-coding capabilities of GPT-5.3-Codex alongside general reasoning, agentic workflows, and professional knowledge work, all in a single model.
Previously, developers had to choose between Codex for coding tasks and reasoning-heavy models for complex analysis. GPT-5.4 collapses that choice. It’s available through three surfaces simultaneously: ChatGPT (as “GPT-5.4 Thinking”), the OpenAI API (as gpt-5.4), and Codex.
The model also arrived in multiple variants. GPT-5.4 Thinking is the flagship reasoning version for paid users. On the other hand, GPT-5.4 Pro targets maximum performance for complex professional tasks and is available on Pro and Enterprise plans. GPT-5.4 Mini (released March 17, 2026) provides limited access to free-tier users through the Thinking feature. GPT-5.4 Nano is the smallest variant designed for edge and embedded use cases via the API only.
What’s Actually New in ChatGPT 5.4

Reasoning, Coding, and Professional Work, Unified
The most significant thing GPT-5.4 does is bring all three capability domains together into a single model. Consequently, you no longer have to switch between models depending on whether your task is primarily reasoning, coding, or professional document work. OpenAI deliberately designed this unification, and the benchmark results reflect it.
On GDPval, a benchmark that tests AI on real professional knowledge work tasks spanning 44 occupations across the top industries contributing to US GDP, including sales presentations, accounting spreadsheets, urgent care schedules, manufacturing diagrams, and short videos, GPT-5.4 matches or exceeds industry professionals in 83% of comparisons, up from 70.9% for GPT-5.2. That jump isn’t trivial.
It means GPT-5.4 is doing knowledge work at a level that outperforms human professionals in four out of five tested cases across a broad range of industries. Consequently, for professionals using ChatGPT as a daily work tool, this improvement in output quality on real deliverables is where you’ll notice the upgrade most clearly.
Native Computer Use: A Genuine Leap
GPT-5.4 introduces native Computer Use capabilities, the ability to interact directly with desktop environments, navigate software interfaces, and complete tasks inside applications without human step-by-step guidance. On OSWorld-Verified, the benchmark that scores AI ability to use desktop environments, GPT-5.4 scored 75%, surpassing the human expert baseline of 72.4%.
For comparison, GPT-5.2 scored 47.3% on the same benchmark. That 27.7 percentage-point jump in less than four months is the clearest single signal of how quickly agentic AI capabilities are advancing in 2026.
What This Means Practically: GPT-5.4 can operate software, navigate file systems, fill out forms in applications, extract data from spreadsheets, and complete multi-step workflows inside real programs, not just describe how to do these things. The Computer Use API scores 75% on OSWorld, making it the first model to exceed the human expert baseline on this benchmark credibly.
Upfront Planning: Steer Before It Finishes
One of the most practically useful UX improvements in ChatGPT 5.4 Thinking is the ability to see and adjust the model’s plan before it finishes generating its response. When you submit a complex task, GPT-5.4 Thinking now shows you its intended approach as it works. You can redirect, correct, or refine before the model completes, rather than waiting for a full response, you then have to tear apart and retry.
This matters more than it sounds for long, complex tasks. If you’re asking GPT-5.4 to build a financial model, draft a legal analysis, or refactor a large codebase, catching a wrong assumption at the planning stage saves significantly more time than correcting a completed output. OpenAI calls this steerability, and it’s one of the clearest quality-of-life improvements for power users in this release.
Spreadsheet, Presentation, and Document Performance
OpenAI specifically prioritized improvement in spreadsheet, presentation, and document work with GPT-5.4. On an internal benchmark of spreadsheet modeling tasks that a junior investment banking analyst might complete, GPT-5.4 achieves a mean score of 87.3% compared to 68.4% for GPT-5.2.
That 19-point jump represents a model that went from being inconsistently useful to consistently reliable in the kind of structured-data work professionals do every day. Additionally, ChatGPT for Excel launched in beta alongside GPT-5.4, extending this directly into the tools professionals already use.
Configurable Reasoning Effort
GPT-5.4 introduces five discrete levels of reasoning effort: none, low, medium, high, and xhigh, that let developers control how deeply the model reasons before generating a response. This is an architectural advantage for production systems: you can calibrate cost and latency against task complexity rather than always paying for maximum reasoning depth on simple queries. Therefore, for developers building on the OpenAI API, this configurability is one of the most practically impactful changes in the release.
Factual Accuracy Improvement
OpenAI reported a 33% reduction in factual errors in GPT-5.4 compared to GPT-5.2. Fewer hallucinations and more reliable factual grounding across the full range of professional tasks is the kind of unglamorous improvement that produces genuine day-to-day reliability gains.
For users who’ve experienced the frustration of a confidently wrong AI response in a professional context, this reduction is meaningfully useful.
ChatGPT 5.4 vs Previous GPT Models
Model | Release | SWE-bench | OSWorld | GDPval | Best For |
GPT-4o | May 2024 | ~49% | ~38% | ~55% | Everyday tasks, free tier |
GPT-5 | Aug 2025 | ~73% | ~55% | ~66% | General professional use |
GPT-5.2 | Dec 2025 | ~77% | 47.3% | 70.9% | Professional knowledge work |
GPT-5.3 Codex | Feb 2026 | 74.0% | — | — | Agentic coding |
GPT-5.4 | Mar 2026 | ~80% | 75% | 83% | Professional + coding + agents |
GPT-5.4 vs GPT-4o

The gap here is substantial. If you’re still on GPT-4o as your primary tool and regularly do complex reasoning, professional document work, or coding, the quality difference between these two models is large enough to notice in daily use. GPT-4o remains the baseline for free users and is genuinely good for simple everyday tasks, but for anything requiring sustained reasoning or professional-grade output, GPT-5.4 is a meaningful step up.
GPT-5.4 vs GPT-5.2
The improvements over GPT-5.2 are focused and targeted rather than broadly sweeping. The coding unification (bringing GPT-5.3-Codex capabilities into the mainline model), the computer use jumped from 47.3% to 75%, and the GDPval professional work improvement from 70.9% to 83% are the three places where the difference is most significant. Therefore, if GPT-5.2 already handled your workflow well, 5.4 produces meaningfully better results on your hardest tasks without changing what already worked.
GPT-5.4 vs GPT-5.3 Codex
These aren’t competitors; they’re complementary. GPT-5.3 Codex was optimized specifically for agentic coding pipelines at lower cost and latency.
GPT-5.4 incorporates GPT-5.3 Codex’s coding capabilities while adding reasoning depth, computer use, and professional work performance. If you’re running a high-volume, latency-sensitive coding pipeline, GPT-5.3 Codex may still be the right choice.
However, for everything else, GPT-5.4 does the job better. And, for a full picture of how ChatGPT’s capabilities have evolved from GPT-4 to the GPT-5 family, our ChatGPT-4 guide covers the earlier architecture and what changed across generations.
ChatGPT 5.4 vs Claude Opus 4.6
This is the comparison most professionals are actually watching. GPT-5.4 and Claude Opus 4.6 are the two most capable frontier models available in early 2026, and they trade leads across different categories. For instance, on:
Coding

GPT-5.4 scores approximately 80% on SWE-bench Verified, essentially neck-and-neck with Claude Opus 4.6’s 80.8%. The gap that existed six months ago has effectively closed. Both models are now elite-tier coding tools, and the practical difference in everyday coding tasks is minimal.
Where Claude still holds an edge is in very large codebase analysis. Its 1M token context window versus GPT-5.4’s standard 272K context, which is meaningful when you need to analyze or refactor a massive monorepo.
For how to get the most out of Claude, specifically for coding workflows, our Claude AI for Coding guide covers the specific prompting approaches and workflow setups that produce the best results.
Computer Use
GPT-5.4 leads. Its 75% OSWorld score, above the human expert baseline, is a genuine differentiator. Claude’s computer use capabilities are strong, but GPT-5.4’s native integration gives it a meaningful practical advantage for agentic tasks that involve operating desktop software.
Professional Knowledge Work
GPT-5.4’s 83% GDPval score and specific spreadsheet improvements give it an edge on structured professional document production. Claude remains stronger on nuanced long-form writing quality and stylistic precision; professional writers who care deeply about prose quality still prefer Claude’s output.
Multimodal
GPT-5.4 leads. Native DALL-E image generation, image analysis, and voice mode are capabilities Claude doesn’t match for image generation specifically. If your workflow involves generating visual content, GPT-5.4 is the only realistic choice between the two.
Context Window
Claude still leads for very large document analysis. GPT-5.4’s standard 272K context (with a surcharge above that threshold) versus Claude’s 1M-token window matters most when you’re processing very large files: full codebases, book-length documents, or extensive research sets.
The Honest Summary
GPT-5.4 has closed the gap with Claude on coding and extended its lead on computer use and professional document work. Claude maintains advantages in long-form writing quality, large-context document analysis, and instruction-following on very complex multi-step tasks. Neither model has made the other irrelevant; the right choice still depends on your primary use case.
For a broader look at how these two AI platforms compare across all dimensions, our AI Unboxed section provides a comprehensive overview of AI tools and model comparisons.
How ChatGPT 5.4 Compares to Other AI Models
Beyond Claude, GPT-5.4 competes against a broader field. For a direct side-by-side with Grok, xAI’s model that has emerged as another serious competitor in the professional AI space, our Grok vs ChatGPT comparison covers where Grok leads, where ChatGPT leads, and which use cases favor which platform.
Additionally, DeepSeek has attracted significant attention as a lower-cost alternative from a Chinese AI lab. Our DeepSeek vs. ChatGPT comparison examines whether the cost advantage translates into real-world performance in professional workflows.
Pricing and Access
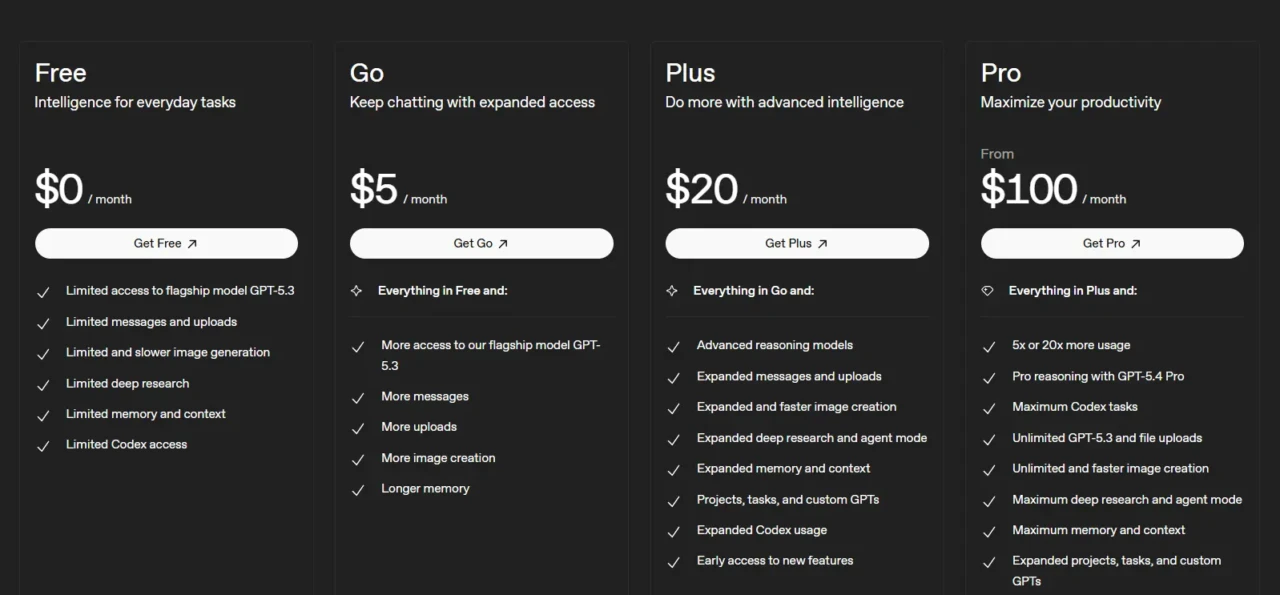
Understanding exactly who can use GPT-5.4 and what it costs is critical before making any plan decision.
Plan | Monthly Cost | GPT-5.4 Access | Notable Inclusions |
Free | $0 | GPT-5.4 Mini only (via Thinking feature) | Limited; GPT-5.4 Mini as fallback |
ChatGPT Plus | $20/month | ✅ GPT-5.4 Thinking | GPT-5.4, image gen, voice, web search, 80 Thinking messages per 3hr |
ChatGPT Pro | $100/month | ✅ GPT-5.4 + GPT-5.4 Pro | Dedicated GPU, unlimited GPT-5.4 access, 10x more Codex usage than Plus |
ChatGPT Pro (High) | $200/month | ✅ GPT-5.4 + GPT-5.4 Pro | Maximum usage, guaranteed compute allocation |
ChatGPT Business | $25/user/month | ✅ GPT-5.4 Thinking | Team workspace, admin controls, 3-user minimum |
Enterprise | Custom | ✅ Full GPT-5.4 suite | Security, compliance, dedicated support, and early access via admin settings |
OpenAI API | Per token | ✅ Standard: $2.50/$15 per MTok | Pro variant: $30/$180 per MTok; 272K standard context |
The Honest Access Picture: GPT-5.4 Thinking requires a minimum of a ChatGPT Plus subscription at $20/month. Free users get GPT-5.4 Mini, a capable fallback that scores 54.38% on SWE-bench Pro compared to Standard’s 57.7%, but not the flagship model. The new $100/month Pro tier launched alongside GPT-5.4 and offers dedicated GPU allocation (no shared-compute latency spikes) plus unlimited access, worth evaluating if you’re a heavy user who regularly hits Plus rate limits.
One Important Caveat for API Users: The standard context window for GPT-5.4 is 272K tokens. Any input above that threshold is billed at $5.00 per million tokens instead of $2.50, a 2x multiplier that significantly affects cost for users routinely pushing large contexts. Plan your usage accordingly.
Is ChatGPT 5.4 Worth It?
Rather than a vague answer, here’s the direct breakdown based on your situation.
GPT-5.4 Is Worth Upgrading to If…
- You currently use GPT-4o as your primary tool and regularly hit its limitations when dealing with complex reasoning, multi-step professional tasks, or coding. The quality improvement over GPT-4o is significant enough to notice in daily use.
- You do professional knowledge work involving spreadsheets, presentations, financial models, or legal documents. The 87.3% spreadsheet benchmark score and 83% GDPval professional work performance are tangible improvements in the quality of the output you’ll receive.
- You’re a developer or a member of an enterprise team building agentic workflows. The native computer-use capabilities, configurable reasoning effort, and tool-ecosystem improvements are specifically designed for production AI systems.
It’s Not An Urgent Change If…
- You primarily use ChatGPT for simple everyday tasks, such as basic writing, quick Q&A, and routine summaries, where GPT-4o already serves you well, and the improvement delta doesn’t meaningfully change your output.
- You’re a Claude user, and your primary work involves long-form writing quality or analysis of very large documents. GPT-5.4 has closed gaps but hasn’t reversed Claude’s advantages on these specific tasks.
- You’re cost-conscious and on the free tier. GPT-5.4 Mini is a capable free-tier fallback, and GPT-4o remains genuinely strong for most everyday use.
The Honest Bottom Line

ChatGPT 5.4 is the most significant GPT-5 update since the family launched. The computer use improvement from 47.3% to 75%, the professional knowledge work improvement to 83% on GDPval, the coding unification with GPT-5.3 Codex, and the 33% reduction in factual errors are real advances across every benchmark that matters for professional use.
It’s not a new AI era; it’s the current era getting meaningfully better. Consequently, if your work demands serious AI capability, GPT-5.4 Thinking on the Plus plan is the most capable $20/month you can spend on AI right now.
FAQs
ChatGPT 5.4 (officially GPT-5.4) is OpenAI’s flagship model released on March 5, 2026. It’s the first model in the GPT-5 family to unify advanced reasoning, frontier coding capabilities (from GPT-5.3-Codex), and native computer use in a single architecture. It’s available in ChatGPT as GPT-5.4 Thinking and through the OpenAI API.
GPT-5.4 Mini, a lighter version that scores 54.38% on SWE-bench Pro, is available to free-tier users through the Thinking feature in the + menu. The flagship GPT-5.4 Thinking model requires a ChatGPT Plus subscription ($20/month) or higher. GPT-5.4 Pro is available on the $100/month or $200/month Pro plans and Enterprise plans only.
It depends on the task. GPT-5.4 leads on computer use (75% OSWorld vs Claude’s lower score), professional document work (83% GDPval), and multimodal capabilities, including image generation. Claude Opus 4.6 still leads in long-form writing quality, large-context document analysis (1M-token context window vs. GPT-5.4’s 272K standard), and instruction-following reliability on very complex multi-step tasks. On coding, both are now essentially tied at approximately 80% SWE-bench Verified.
GPT-4o is still the baseline model for free users and a strong everyday tool. GPT-5.4 is substantially more capable in complex reasoning, professional knowledge work, coding, and computer use. The quality gap between GPT-4o and GPT-5.4 is large enough to notice clearly in daily professional use. GPT-5.4 is not a minor refinement over GPT-4o but a full generation ahead on hard tasks.
For professional users doing complex work, such as coding, financial modeling, legal analysis, research, or any field requiring sustained reasoning and reliable output, yes. The $20/month Plus plan gives you GPT-5.4 Thinking, image generation, voice mode, and web search. For casual users doing simple everyday tasks, GPT-4o on the free tier remains capable, and the upgrade may not justify the cost.
In ChatGPT, GPT-5.4 Thinking appears as “Thinking” in the model picker for Plus, Team, and Pro subscribers. GPT-5.2 Thinking remains available until June 5, 2026, under Legacy Models. GPT-5.4 Mini is available to free users via the + menu’s Thinking option. Via the OpenAI API, use the model ID gpt-5.4 for the standard model or gpt-5.4-pro for the Pro variant; verify current pricing at platform.openai.com.
Conclusion

ChatGPT 5.4 is the most capable model OpenAI has shipped, not by a dramatic margin on any single benchmark, but by a consistent, meaningful improvement across every dimension that matters for professional work. The computer use jumped from 47.3% to 75%, the 83% GDPval professional knowledge work score, the coding unification that eliminates the need to choose between reasoning and Codex models, and the 33% reduction in factual errors combine to make GPT-5.4 a genuinely better daily tool for anyone doing serious professional work with AI. The upfront planning feature in GPT-5.4 Thinking alone saves significant time on complex tasks by letting you correct direction before the model finishes, rather than after.
Whether it changes your setup depends on where you’re starting. For instance, if you’re on GPT-4o, the upgrade to Plus for GPT-5.4 access is easy to justify. And, if you’re a Claude user focused on writing quality and large document analysis, GPT-5.4 has closed the gaps without reversing your tool preference. However, if you’re a developer building agentic systems, GPT-5.4’s computer use capabilities, configurable reasoning effort, and Codex integration are the most significant API advances since GPT-5 launched. Whatever your workflow, GPT-5.4 is the clearest single answer to “what’s the best general-purpose AI model available right now.” That answer is unlikely to change until the next iteration lands.
Every major AI release, honest review, and practical breakdown of what actually matters, all in one place at YourTechCompass.com, where we cut through the noise so you don’t have to.


