
I’ll be honest with you, I wasn’t expecting much when the AI world started buzzing about DeepSeek-V4. We’ve had a lot of “game-changing” model releases this year, and most of them shift the benchmarks by a few percentage points before the hype cycle moves on. DeepSeek-V4 is different. Released as a public preview on April 24, 2026, it arrived with a 1.6-trillion-parameter architecture, a 1-million-token context window as standard, open-source weights on Hugging Face, and API pricing that makes every major US lab look like they’re charging for a luxury service. Oh, and it runs on Huawei chips, not NVIDIA. If that last point doesn’t tell you something about where the global AI race is heading, read the rest of this article.
This review is for you if you’re a developer deciding whether to build on DeepSeek-V4, a business owner evaluating whether it can cut your AI spend, an AI enthusiast tracking the competitive landscape, or someone who simply wants to understand why a Chinese lab releasing a language model in April 2026 is being described as a geopolitical event. I’ve researched the architecture, benchmarks, pricing, competition, and the honest limitations, so you can make a clear-eyed decision. You’ll find everything you need, without the hype. Let’s get into it.
Before we get into it: this review is independent. No brand paid for coverage, and no score was negotiated. If you want to see exactly how we evaluate tools: what we test, how we score, and how we handle affiliate relationships, our Review Methodology has all of it.
What Is DeepSeek-V4? A Clear-Eyed Introduction
DeepSeek is a Chinese AI research lab founded in 2023 by High-Flyer, a Hangzhou-based quantitative hedge fund, and led by Liang Wenfeng. It first grabbed global attention in January 2025 when its R1 reasoning model matched OpenAI’s o1 at approximately 90% lower API costs, briefly triggering a $1 trillion tech stock selloff, including $600 billion wiped from NVIDIA’s market cap in a single day. DeepSeek-V4 is the company’s most significant release since that moment.
To understand where V4 sits, you need to know the lineage. DeepSeek-V2 (May 2024) introduced the mixture-of-experts architecture at shockingly low cost. DeepSeek-V3 (December 2024) scaled that to 671 billion parameters and trained the entire model for approximately $5.6 million, a number that made Western AI labs deeply uncomfortable.
DeepSeek-R1 (January 2025) was a reasoning-specialist model that matched OpenAI’s o1 on mathematics and code benchmarks. DeepSeek-V3.2 followed through late 2025 with incremental improvements and a 128,000-token context window. V4 is the fourth-generation flagship, and according to DeepSeek’s own API changelog, it officially launched on April 24, 2026.
V4 ships in two variants. V4-Pro is the flagship: 1.6 trillion total parameters with 49 billion activated per token, pre-trained on 33 trillion tokens. V4-Flash is the learner option: 284 billion total parameters with 13 billion active, trained on 32 trillion tokens.
Both variants are open-source under an MIT license, available on Hugging Face, and currently in public preview. The name “preview” matters; DeepSeek has not yet committed to a finalized release timeline, and benchmark scores are still being independently verified. That context is important for everything that follows.
What’s New in DeepSeek-V4: Key Upgrades Over V3

Here’s what actually changed, and why it matters to you practically, not just technically.
A 1-Million-Token Context Window Built In, Not Bolted On
This is the headline architectural upgrade. Most large language models treat long context as a premium add-on that gets expensive fast. DeepSeek-V4 was built from the ground up with one million tokens as the default native context length, roughly 750,000 words, or an entire multi-file codebase, or a long legal document corpus, processed in a single pass.
Furthermore, at that full one-million-token context length, V4-Pro uses only 27% of the per-token inference compute required by V3.2. V4-Flash pushes efficiency further, just 10% of V3.2’s KV cache memory at the 1M setting. Consequently, the pricing can be this aggressive because the model genuinely costs less to run at scale.
Hybrid Attention: The Architecture That Makes It Possible
V4 solves the biggest technical problem with long-context models: the quadratic compute cost of standard attention. The longer the context, the more expensive every computation becomes, which is why most models either cap context or charge heavily for it.
DeepSeek’s solution is a hybrid of Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). CSA reduces the number of key-value pairs the model attends to at each layer, cutting compute for long sequences.
HCA applies aggressive compression to distant context while preserving the model’s ability to retrieve information from early in a long document. Moreover, a Lightning Indexer running in FP8 with ReLU-activated scoring selects only the most relevant compressed tokens for full attention, reducing attention complexity from quadratic to roughly O(Lk), where k is much smaller than the full sequence length.
Stronger Reasoning and the Engram Memory Architecture
V4 integrates Engram (DeepSeek’s conditional memory system, published in a January 2026 research paper), which separates static pattern retrieval from dynamic reasoning. In practice, this means the model can selectively retain and recall information based on task context, rather than treating all context tokens equally.
For coding, this translates into a genuine understanding of the project’s structure, naming conventions, and logical dependencies throughout the repository. Additionally, on SuperGPQA (graduate-level scientific reasoning), V4-Pro-Base reached 53.9 compared to V3.2’s 45.0. On FACTS Parametric, it more than doubled its predecessor’s performance, jumping from 27.1 to 62.6.
Agentic Capabilities and Dual-Mode Operation
V4 is designed for agent workflows, not just chat interactions. DeepSeek says it has been using V4-Pro internally as its primary agentic coding assistant, with internal performance described as above, Claude Sonnet 4.5 and close to Claude Opus 4.6 in non-thinking mode.
Furthermore, both V4 variants offer Thinking and Non-Thinking modes, configurable via an API parameter. The DeepSeek app’s April 8 redesign maps these to “Expert Mode” (V4-Pro handling complex reasoning) and “Fast Mode” (V4-Flash handling simpler tasks). V4 is also compatible with mainstream development frameworks, including Claude Code, OpenClaw, OpenCode, and CodeBuddy.
What V4 Is Not
Honest framing matters here. Contrary to pre-release speculation, V4 is still a text-only language model. DeepSeek delayed the development of multimodal generation and understanding capabilities due to computing power constraints and strategic prioritization.
You will not be getting image generation, video understanding, or voice input in this release. Additionally, the preview label is real; V4’s benchmark scores are currently listed as internal claims pending third-party reproduction.
Benchmark Performance: How Does It Actually Stack Up?
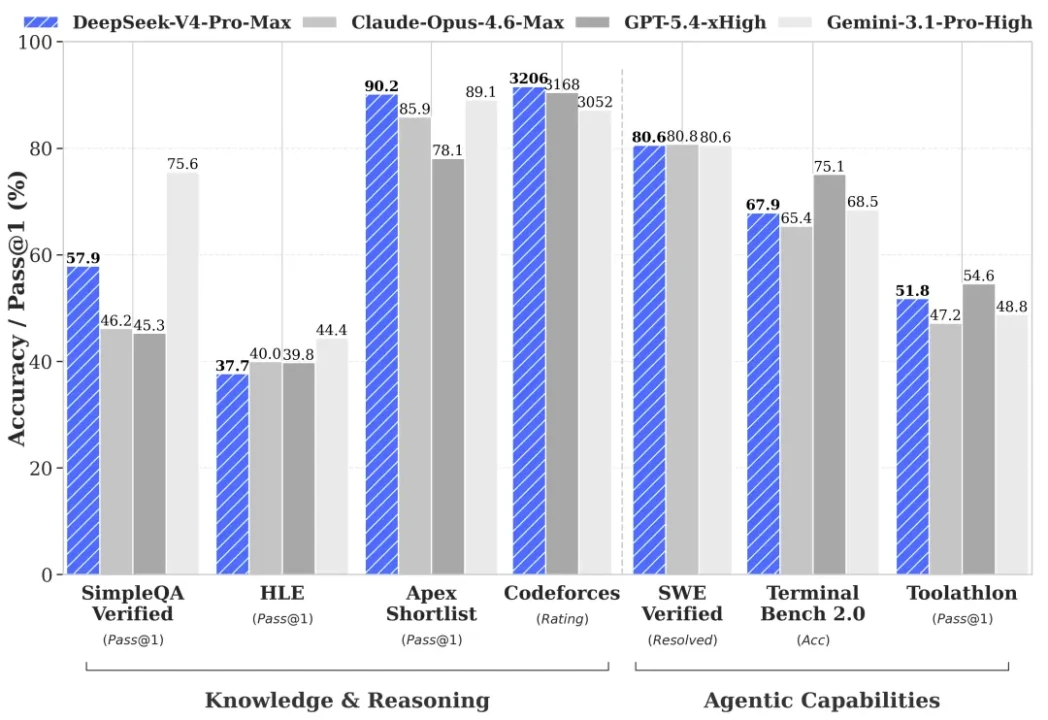
Let me walk you through what the numbers actually show, with the appropriate caveats.
V4-Pro’s strongest results come from mathematics and competitive programming. On Putnam-2025, DeepSeek’s V4-Pro-Max achieves a perfect 120/120 score.
On HMMT 2026 February, it scored 95.2, closely trailing GPT-5.4 (97.7) and Claude Opus 4.7 (96.2) but ahead of Gemini 3.1 Pro. But, on IMOAnswerBench, V4-Pro-Max scores 89.8, ahead of Claude (75.3) and Gemini (81.0), with GPT-5.4 edging ahead at 91.4. And on Codeforces competitive programming, V4-Pro scores 3,206; the highest-rated score of any model at release, surpassing GPT-5.4’s 3,168.
On real-world software engineering, V4-Pro scores 80.6% on SWE-Bench Verified, within 0.2 percentage points of Claude Opus 4.6 (80.8%) and matching Gemini 3.1 Pro (80.6%). And, on LiveCodeBench (coding quality across diverse tasks), V4-Pro scores 93.5%, ahead of Gemini (91.7%) and meaningfully ahead of Claude (88.8%). While on Terminal-Bench 2.0 (autonomous terminal execution with a 3-hour timeout), V4-Pro scores 67.9%, beating Claude Opus 4.6 (65.4%) and competitive with Gemini (68.5%), while GPT-5.5 Thinking leads the full comparison set at 75.1%.
That said, V4 has real gaps against the very latest closed-source frontier models. On Humanity’s Last Exam (HLE) (expert-level cross-domain reasoning), V4-Pro scores 37.7%, behind Claude (40.0%), GPT-5.4 (39.8%), and well behind Gemini 3.1 Pro (44.4%).
On SimpleQA-Verified (factual knowledge retrieval), V4-Pro scores 57.9% versus Gemini’s 75.6%, a meaningful gap if your use case requires real-world knowledge recall. Additionally, V4-Flash falls 1.6 points behind V4-Pro on SWE-Bench (79.0% vs 80.6%), a narrow gap, but important context for choosing between variants.
DeepSeek’s own technical report acknowledges that V4 trails GPT-5.4 and Gemini 3.1 Pro by approximately three to six months in overall capability. That’s honest. It’s also not a dealbreaker, given the pricing.
Benchmark Comparison Table
Benchmark | DeepSeek V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro |
SWE-Bench Verified (coding) | 80.6% | N/A | 80.8% | 80.6% |
LiveCodeBench | 93.5% | N/A | 88.8% | 91.7% |
Codeforces Rating | 3,206 | 3,168 | N/A | 3,052 |
Terminal-Bench 2.0 | 67.9% | 75.1% | 65.4% | 68.5% |
HMMT 2026 (math) | 95.2% | 97.7% | 96.2% | N/A |
IMOAnswerBench | 89.8% | 91.4% | 75.3% | 81.0% |
Putnam-2025 (math) | 120/120 | N/A | N/A | N/A |
HLE (expert reasoning) | 37.7% | 39.8% | 40.0% | 44.4% |
SimpleQA Verified | 57.9% | N/A | N/A | 75.6% |
Note: V4 benchmark scores are currently DeepSeek internal claims pending third-party independent reproduction. All scores sourced from DeepSeek’s technical report and independent evaluations as of April 2026.
How to Access and Use DeepSeek-V4

Getting started with DeepSeek-V4 is straightforward and notably more accessible than most frontier models at this performance level.
DeepSeek Chat (Web and App)
The simplest way to use DeepSeek-V4 is through chat.deepseek.com; the official web interface and mobile app, both available for free. Since the April 8 redesign, the app runs V4-Pro in Expert Mode for complex reasoning tasks, and V4-Flash in Fast Mode for everyday queries. You don’t need an API key, a credit card, or any setup to start experimenting today.
DeepSeek API
For developers building applications, the API is live at api-docs.deepseek.com. Both V4 variants use the OpenAI ChatCompletions and Anthropic API formats, meaning that if you’re already calling GPT or Claude in your codebase, switching to DeepSeek-V4 requires changing only the model parameter, not your integration architecture.
Both models support a 1M-token context window and a maximum output of 384,000 tokens. Additionally, legacy aliases deepseek-chat and deepseek-reasoner currently route to V4-Flash non-thinking and thinking modes, respectively, but will be fully retired on July 24, 2026. Migrate to explicit deepseek-v4-flash and deepseek-v4-pro model IDs before that date.
Open-Weight Download
Both V4 variants are published under the MIT license in DeepSeek’s Hugging Face collection, meaning you can download the weights, run them locally, and fine-tune them for your specific use case. V4-Flash can reportedly run on a single NVIDIA H100 80GB GPU with sufficient system RAM.
V4-Pro, at 1.6 trillion parameters, requires workstation or data center-level infrastructure. Huawei Ascend 950 chips also provide full compatibility for those operating outside the NVIDIA ecosystem.
Third-Party Access
DeepSeek-V4-Flash is already available through OpenRouter at $0.14 per million input tokens and $0.28 per million output tokens. Consequently, you can access V4 through aggregators you’re already using, without setting up a separate DeepSeek account.
Important Regional Note: DeepSeek’s API routes through servers based in China. If your application handles data subject to GDPR, HIPAA, or other jurisdictional regulations, review the data residency implications carefully before deploying through the hosted API. Self-hosting via Open Weights removes this concern entirely.
Real-World Use Cases: What You Can Actually Do With It
Here’s where DeepSeek-V4 becomes genuinely practical. Let me walk you through who gets the most value from it.
Developers and Engineers

V4-Pro is the strongest open-source model for competitive programming and one of the closest challengers to closed-source models on real-world software engineering tasks. If you’re building an AI coding assistant, reviewing and debugging complex multi-file codebases, or running automated software engineering workflows, V4-Pro’s 80.6% SWE-Bench score and 3,206 Codeforces rating are the highest available from any open-weight model.
Furthermore, its native 1M context means you can feed an entire codebase into a single prompt without context management gymnastics. Consequently, for developers who want to self-host for air-gapped or privacy-sensitive applications, the MIT license makes V4 one of the few frontier-class models you can actually deploy on your own infrastructure.
Business Owners and Entrepreneurs
Here’s the number you need: V4-Pro output costs $3.48 per million tokens, compared to $30 per million for GPT-5.5 and $25 for Claude Opus 4.6. That’s approximately 9x cheaper than GPT and 7x cheaper than Claude for frontier-class performance.
Moreover, V4-Flash pushes costs to just $0.28 per million output tokens, making it viable for high-volume use cases such as content moderation, data extraction, customer service automation, and document summarization, at a cost that simply wasn’t accessible before. Therefore, if you’re running a business that processes large volumes of text through AI, and you’re currently paying OpenAI or Anthropic rates, the cost reduction math from switching to V4 (or at least benchmarking it for your workload) is straightforward.
Researchers and Students
V4’s 1M-token context window is a genuine research tool. You can feed entire academic corpora, multi-year report archives, or complete legal case histories into a single session and ask questions in plain language.
Additionally, V4’s improved multilingual support, including coverage of non-English and lower-resource languages, makes it more useful for global research than earlier DeepSeek versions. For mathematics specifically, a perfect 120/120 on Putnam-2025 puts V4 in a category few models occupy.
African Tech and Emerging Market Context
This is worth addressing directly because it matters to readers following developments in AI in Africa. DeepSeek-V4’s combination of low cost, open weights, and improving multilingual performance makes it one of the most practically relevant frontier AI releases for Africa’s developer and entrepreneur ecosystem.
The model’s efficiency-first architecture (designed to run at dramatically lower compute costs) aligns directly with the constraint-driven AI development philosophy that African builders are pioneering. Furthermore, as Microsoft’s 2026 AI Adoption report noted, DeepSeek usage in Africa is estimated to be 2 to 4 times higher than in other regions, driven specifically by cost accessibility and the removal of credit card barriers. For African developers building AI applications on tight infrastructure budgets, V4-Flash at $0.28 per million output tokens is a fundamentally different proposition from $25-$30 frontier model pricing.
DeepSeek-V4 vs The Competition: Honest Head-to-Head
Let me give you the direct comparison across the four models most buyers are choosing between. For deeper dives into individual models, you can read our ChatGPT breakdown and our Claude Opus 4.7 review.
DeepSeek-V4 vs. GPT-5.4 (OpenAI)
On coding benchmarks that DeepSeek publishes comparisons for, V4-Pro either matches or leads GPT-5.4, including a higher Codeforces rating (3,206 vs. 3,168) and competitive SWE-Bench performance. However, GPT-5.5 Thinking leads the full comparison set on terminal and computer-use tasks, with a 15-point advantage over V4-Pro on Terminal-Bench 2.0.
Additionally, GPT-5.4 leads on HMMT 2026 math (97.7% vs. 95.2%) and holds an edge in general knowledge tasks. Furthermore, ChatGPT’s consumer ecosystem (plugins, memory, multimodal input, and an established developer community) has no equivalent on DeepSeek’s side.
The Honest Verdict: DeepSeek-V4 competes seriously on coding and mathematics at a fraction of the price. For everything else, the OpenAI ecosystem still leads on depth and breadth.
DeepSeek-V4 vs. Claude Opus 4.6 (Anthropic)
This is the closest performance matchup in the comparison set. V4-Pro and Claude Opus 4.6 are within 0.2 percentage points on SWE-Bench Verified (80.6% vs. 80.8%). In addition, V4-Pro leads on LiveCodeBench (93.5% vs. 88.8%) and Terminal-Bench 2.0 (67.9% vs. 65.4%).
Claude, on the other hand, leads on HMMT math (96.2% vs. 95.2%) and HLE expert reasoning (40.0% vs. 37.7%). Moreover, Claude’s strengths in nuanced writing, instruction following, and safety-oriented design remain real differentiators.
Therefore, if your application requires consistent, safety-conscious, high-quality long-form writing, Claude is the better choice. However, for coding-heavy workloads, V4-Pro delivers comparable performance at approximately 7x lower output cost.
That’s a meaningful difference at the production scale. You can also explore our full AI Unboxed category for more model comparisons.
DeepSeek-V4 vs. Gemini 3.1 Pro (Google)
Gemini 3.1 Pro is the overall benchmark leader across the broadest range of tests, topping 13 of 16 major benchmarks according to independent April 2026 evaluations, with an MMLU score of 94.1% and a GPQA Diamond score of 94.3% (the highest among models). On factual knowledge retrieval (SimpleQA-Verified: 75.6% vs. 57.9%) and expert reasoning (HLE: 44.4% vs. 37.7%), Gemini holds a clear and meaningful edge over V4.
Additionally, Gemini’s deep integration with Google’s ecosystem (Workspace, Search, YouTube) has no equivalent in DeepSeek’s offering. Consequently, if your workload requires accurate recall of real-world knowledge or tight integration with the Google ecosystem, Gemini is the stronger choice. DeepSeek leads on cost and holds competitive ground on pure coding tasks.
DeepSeek-V4 vs. Llama 3 (Meta)
Both are open-weight models, the most important point of similarity. Llama 3 has a significantly larger Western developer ecosystem, more fine-tuning community work, and stronger institutional adoption in enterprise environments.
However, DeepSeek-V4 outperforms Llama 3 on reasoning benchmarks and benefits from a much larger active parameter count. Additionally, DeepSeek’s pricing infrastructure (hosted API, web interface, and OpenAI-compatible integration) is more mature than Llama’s self-hosting-first model. Consequently, for developers who want open-weight performance without mandatory self-hosting, V4 currently holds the stronger position.
Head-to-Head Summary
Comparison | DeepSeek V4-Pro Advantage | Competitor Advantage |
vs. GPT-5.4 | Price (9x cheaper output), Codeforces rating | Terminal-Bench, HMMT math, consumer ecosystem |
vs. Claude Opus 4.6 | Price (7x cheaper), LiveCodeBench, Terminal-Bench | Nuanced writing, instruction following, safety design |
vs. Gemini 3.1 Pro | Price, coding benchmarks | MMLU, HLE, SimpleQA, Google ecosystem |
vs. Llama 3 | Reasoning benchmarks, hosted infrastructure | Western developer ecosystem, fine-tuning community |
The Controversy and the Questions You Should Be Asking
This section exists because responsible AI evaluation requires naming the real concerns rather than burying them.
The Data Privacy Question

DeepSeek’s API routes through servers in China. That’s a fact, not a speculation. If you’re using the hosted API to process sensitive personal data, enterprise IP, healthcare records, or legally privileged information, you need to understand the data residency implications.
The US State Department sent a diplomatic cable to embassies worldwide on April 24, 2026, the same day V4 launched, instructing staff to warn foreign governments about alleged IP theft by DeepSeek and other Chinese AI firms. That warning is significant context.
However, the self-hosting path via open weights directly addresses this concern. If data sovereignty is a concern for your use case, download the weights and run V4 on your own infrastructure. The MIT license makes that entirely legal and straightforward.
The Huawei Chip Story
V4 is the first major frontier AI release to be trained on and deployed using Huawei Ascend 950 chips rather than NVIDIA hardware, as confirmed by Reuters on April 24, 2026. This is geopolitically significant: it demonstrates that frontier-class AI models can now be trained entirely outside the NVIDIA ecosystem, which directly undermines the strategic logic of US chip export controls.
DeepSeek’s earlier V3 model was trained on NVIDIA H800 GPUs, and the company has faced multiple investigations over whether it acquired restricted chips through intermediaries in Singapore. V4 sidesteps that supply chain entirely. Consequently, NVIDIA’s CEO has been explicitly critical of the release.
Censorship and Content Restrictions
DeepSeek models have documented restrictions on politically sensitive topics, particularly those related to the Chinese government, Tiananmen Square, Taiwan, and related subjects. This is not a hypothetical limitation.
If your use case involves politically sensitive global affairs, journalism, or research into subjects that conflict with the Chinese government’s information policy, DeepSeek-V4 will restrict or decline to engage. That’s a real limitation that you need to factor in, honestly, before deploying it in any application where those topics might arise.
The Preview Label
As of April 28, 2026, DeepSeek-V4 is still in public preview. DeepSeek has not committed to a final release timeline. Benchmark scores are reported internally and are pending third-party reproduction.
API behavior may change as the model finalizes. The reasonable posture for production evaluation is to benchmark V4-Flash against your current model route immediately, while maintaining a rollback path until preview behavior settles.
Who Should Use DeepSeek-V4 And Who Shouldn’t

Here’s the practical segmentation you need before making a decision.
Use DeepSeek-V4 if:
- You’re a developer who wants the strongest available open-weight model for coding and mathematical reasoning at low or zero API cost.
- You’re building applications in resource-constrained environments where the per-token cost difference between DeepSeek and proprietary models translates to real budget impact.
- You want to self-host for data privacy reasons and need a frontier-class model with an MIT license.
- You’re already calling the OpenAI or Anthropic API and want to evaluate a cost-efficient alternative with a compatible integration architecture.
- You’re an African developer or entrepreneur building AI applications on limited infrastructure budgets. V4-Flash at $0.28 per million output tokens is worth immediate evaluation.
Be cautious or avoid if:
- Your application processes sensitive personal data through the hosted API, and data jurisdiction matters for compliance.
- You need guaranteed, well-documented content moderation and safety for consumer-facing products, particularly for politically sensitive topics.
- You’re in a regulated industry (healthcare, finance, legal) where data-sovereignty requirements prohibit routing data through Chinese-hosted servers.
- You need production-stable, finalized model behavior immediately; the preview label is real, and benchmark scores are still pending third-party verification.
- Your use case requires multimodal input (image understanding, video, or voice). V4 cannot serve that need in its current release.
For a broader look at how AI tools in this category compare, our DeepSeek vs. ChatGPT breakdown and our DeepSeek AI explained guide provide useful additional context.
FAQs
DeepSeek-V4 is the fourth-generation flagship model from DeepSeek, released as a public preview on April 24, 2026. It comes in two variants: V4-Pro (1.6 trillion parameters, 49 billion active parameters) and V4-Flash (284 billion parameters, 13 billion active parameters). Compared to V3, the biggest changes are: a 1-million-token native context window built into the architecture (versus V3’s 128K), a new hybrid attention mechanism (CSA + HCA) that reduces inference compute to 27% of V3.2 at 1M tokens, an integrated Engram conditional memory architecture for better long-context reasoning, and training on Huawei Ascend chips rather than NVIDIA hardware.
The web interface at chat.deepseek.com is free. The API is usage-based. V4-Flash costs $0.14 per million input tokens and $0.28 per million output tokens at standard pricing. V4-Pro costs $1.74 per million input tokens and $3.48 per million output tokens, with a 75% promotional discount active until May 5, 2026. Additionally, both models are available with open weights on Hugging Face under the MIT license, so you can download and self-host them at no cost.
It depends entirely on what you’re using it for. On competitive programming (Codeforces: 3,206 vs. 3,168) and SWE-Bench Verified coding tasks, V4-Pro is competitive with or ahead of GPT-5.4. However, on terminal and computer-use tasks, HMMT mathematics, and real-world knowledge recall, GPT-5.5 leads. On cost, DeepSeek wins by approximately a factor of 9x in output tokens. There is no single “better” answer; there is a better answer for your specific workload and budget.
Yes, with the appropriate caveats. The API is production-accessible today, and V4-Flash, in particular, at $0.28 per million output tokens, is viable for high-volume business use cases such as document processing, content summarization, and customer service automation. However, if your business operates in a regulated industry or handles personally identifiable information, you need to evaluate whether routing data through DeepSeek’s Chinese-hosted API meets your compliance requirements. Self-hosting via Open Weights removes that concern in most use cases.
For everyday developers and business use cases (coding, writing, research, summarization), the risk profile is manageable. The primary concerns are data privacy (resolved by self-hosting), content restrictions on politically sensitive topics (a real limitation in specific use cases), and the current preview label (model behavior may still change). DeepSeek publishes technical reports but is not currently subject to third-party safety audits equivalent to Anthropic’s or OpenAI’s published evaluations. Consequently, for consumer-facing applications where safety guarantees matter, Claude and GPT-4o class models have more mature, documented safety frameworks.
Yes. Both variants are published under the MIT license on Hugging Face and can be self-hosted. V4-Flash (284 billion parameters) can reportedly run on a single NVIDIA H100 80GB GPU with sufficient system RAM, or on Huawei Ascend 950 hardware. V4-Pro, at 1.6 trillion total parameters, requires workstation or data center-level infrastructure. Local deployment eliminates data privacy concerns and removes dependency on DeepSeek’s hosted API, making it a viable option for developers who need air-gapped environments or are building in regulated industries.
Conclusion

DeepSeek-V4 is not just another model release. It’s a proof point that frontier AI can be built outside Silicon Valley, without NVIDIA hardware, at costs that make every major US lab’s pricing look like a premium markup. A 1.6 trillion-parameter model with a 1-million-token native context window, open-source weights under an MIT license, and an output price of $3.48 per million tokens, compared to $25-$30 for comparable closed-source alternatives, is a genuinely disruptive package. The benchmark gaps against GPT-5.5 and Gemini 3.1 Pro are real, and DeepSeek acknowledges them honestly: approximately three to six months behind the very best frontier models. But for coding-heavy workloads, high-volume API applications, and any context where cost and open access matter, that gap doesn’t change the decision.
The harder questions around data privacy, content restrictions, geopolitical context, and the preview label are also real, and this review has not soft-pedaled them. You’re a grown adult evaluating a tool, and you deserve the full picture. Furthermore, DeepSeek’s trajectory from V2 to V3 to R1 to V4 shows a lab that improves fast, publishes honestly, and prices aggressively. If V4 is already this competitive, the question worth asking isn’t whether DeepSeek can compete; it’s whether the AI industry’s current pricing structure can survive another 12 months of this.
If DeepSeek-V4 is on your radar, don’t just read about it; test it. Spin up V4-Flash on the free web interface today, benchmark it against your current model on a real workload, and let the results speak. The gap between “interesting model” and “replacing my current AI stack” is one honest test away.
For more tech guides and honest reviews, visit YourTechCompass.


