Every major AI conversation in 2025 orbited three names: ChatGPT, Claude, and Gemini. Then, on April 5, 2025, Meta dropped three models in a single announcement, and the conversation shifted. Llama 4 didn’t just update the open-weight AI category. It redefined what open-weight AI can do. Scout, the lightweight variant, ships with a 10-million-token context window; the largest of any openly available model at launch. Maverick, the flagship, deploys 400 billion total parameters while activating only 17 billion per token, achieving frontier-class multimodal performance at a fraction of the compute cost. And Behemoth, the 2-trillion-parameter titan still in training, is already being cited as the teacher model whose knowledge distillation made the other two possible. Meta’s answer to DeepSeek’s efficiency revolution wasn’t a press release. It was three models and a new architectural era.
This article is for you if you’re a developer deciding whether to build on open-weight models instead of paying per token to OpenAI or Anthropic, a researcher who wants to understand and potentially run the model you’re working with, a business owner exploring self-hosted AI for privacy-sensitive applications, or simply someone who wants to understand what Meta has actually built and why it matters. I’ve researched every layer of the Llama 4 family: architecture, benchmarks, access options, real-world use cases, and competitive positioning, and I’ll give you the most honest, most complete Llama 4 breakdown available. No hype. No hedging. Just the full picture.
Before we get into it: this review is independent. No brand paid for coverage, and no score was negotiated. If you want to see exactly how we evaluate tools: what we test, how we score, and how we handle affiliate relationships, our Review Methodology has all of it.
What Is Llama 4, and Why Does Meta Give It Away?
Llama 4 is Meta’s fourth-generation family of open-weight large language models, built by Meta AI, the artificial intelligence research division of Meta Platforms, the company behind Facebook, Instagram, and WhatsApp. Released on April 5, 2025, it represents the most significant architectural shift in the Llama lineage since the family launched in 2023, introducing Mixture-of-Experts (MoE) architecture, native multimodality, and context windows that no competitor at any price point had matched at the time.
The “open-weight” distinction is important and frequently misrepresented, so let me be precise. Llama 4’s weights are publicly available for download, modification, and commercial deployment. However, Meta’s license is not identical to the GPL open-source software.
The Llama 4 Community License Agreement permits free commercial use for most organizations, with one exception: companies with over 700 million monthly active users must obtain a special license from Meta. Additionally, EU-domiciled users and companies are currently prohibited from using or distributing Llama 4 under the current terms, a regulatory complexity that reflects the evolving relationship between AI deployment and European data protection and privacy regulation. For the vast majority of developers, researchers, and businesses globally, those limits are entirely irrelevant to their use case.
Why Does Meta Give This Away?
The strategic logic is the same as it was for Llama 3 and, arguably, more urgent now. The success of DeepSeek’s efficiency-first models reportedly kicked Llama 4 development into overdrive. Meta is said to have scrambled war rooms to understand how DeepSeek lowered the cost of running and deploying models, and the answer was the MoE architecture that Llama 4 now uses.
Commoditizing the AI model layer hurts OpenAI and Anthropic more than it hurts Meta. Furthermore, a global developer community building on Llama generates fine-tunes, integrations, and applications that strengthen Meta’s AI positioning without Meta funding the research. Meta has already integrated Llama 4 into its Meta AI assistant across WhatsApp, Messenger, and Instagram (with rollout in 40 countries), giving it distribution at a scale no other open-source model can match.
The Llama 4 Model Family: Scout, Maverick, and Behemoth
Llama 4 doesn’t offer one model in different sizes. It offers three architecturally distinct models, each designed for a specific deployment context and capability level. Understanding each one helps you make a genuinely informed decision about which fits your situation.
Llama 4 Scout: The Long-Context Lightweight
Scout has 17 billion active parameters, 16 experts, and 109 billion total parameters. Its defining feature is its context window: 10 million tokens; the largest of any openly available model at the time of launch. To put that in perspective, Claude Opus 4.6 supports 1 million tokens, GPT-5.2 supports 128K tokens, and DeepSeek V3.2 supports 128K tokens.
Scout handles roughly 15,000 pages of text in a single session. Consequently, for tasks involving massive document corpora, full codebase analysis, multi-volume research archives, or extended conversation histories, Scout has no open-weight peer.
Scout was designed for accessibility. It runs on a single NVIDIA H100 GPU, using on-the-fly int4 or int8 quantization to minimize performance degradation and enable deployment on smaller hardware footprints.
Furthermore, it was pre-trained on up to 40 trillion tokens covering 200 languages, with fine-tuning support for 12 specific languages, including Arabic, Spanish, German, and Hindi. Scout is the model for developers building personal agents, customer support systems, chatbots, and any application that needs to reason across enormous amounts of context without requiring a data center.
Llama 4 Maverick: The Flagship Multimodal Model
Maverick is Meta’s main workhorse; the model powering Meta AI across Facebook, Instagram, and WhatsApp. It also has 17 billion active parameters, but with 128 experts across 400 billion total parameters, a dramatically denser expert pool than Scout. In addition, its context window is 1 million tokens, and it natively handles both text and image inputs through early-fusion multimodality, meaning visual and language understanding were trained simultaneously rather than retrofitted.
Maverick was built using MetaP hyperparameter scaling, FP8-precision training, and a 30-trillion-token dataset. It was co-distilled from Behemoth, meaning Maverick’s training incorporated knowledge transfer from a model with nearly 2 trillion parameters. Consequently, Maverick delivers capabilities that belie its active parameter count.
It requires an NVIDIA H100 DGX system or equivalent for standard deployment, with FP8 quantized weights available for more efficient operation on compatible hardware. Additionally, its estimated inference cost is approximately $0.19 per million tokens blended on distributed infrastructure, or $0.30 to $0.49 on a single host, making it one of the most cost-competitive frontier-adjacent models available.
Llama 4 Behemoth: The Teacher Model in Training
Behemoth is the crown jewel of the Llama 4 family, and, as of early 2026, its most mysterious member. It has 288 billion active parameters, 16 experts, and nearly 2 trillion total parameters. Also, it is not publicly available.
Meta announced it during the April 2025 launch as still in training and has not provided a specific public release date. Behemoth served as the teacher model for Scout and Maverick during training; its knowledge was distilled into both through a novel co-distillation loss function that dynamically balances soft and hard supervision. Moreover, Behemoth was trained with FP8 precision and optimized MoE parallelism, delivering 10x speedups over Llama 3 training and introducing a new reinforcement learning strategy that incorporates hard prompt sampling and multi-capability batch construction.
Meta’s internal benchmarks show Behemoth consistently outperforming GPT-4.5, Claude 3.7 Sonnet, and Gemini 2.0 Pro on STEM benchmarks, including MATH-500, GPQA Diamond, and BIG-Bench, though it did not surpass Gemini 2.5 Pro on all benchmarks. When Behemoth’s weights are eventually released, the hardware requirements will be significant, multi-node GPU clusters, positioning it primarily for research labs and large enterprise deployments.
Llama 4 Model Family Comparison
Model | Active Params | Total Params | Experts | Context Window | Multimodal | Availability | Best For |
Llama 4 Scout | 17B | 109B | 16 | 10M tokens | ✅ Yes | ✅ Public | Long-context; single GPU; agents |
Llama 4 Maverick | 17B | 400B | 128 | 1M tokens | ✅ Yes | ✅ Public | Enterprise; general assistant; creative |
Llama 4 Behemoth | 288B | ~2T | 16 | TBC | ✅ Yes | ❌ In training | Research frontier; STEM reasoning |
How Llama 4 Works: Key Technical Concepts, Simply Explained

You don’t need to be an ML engineer to understand why Llama 4 performs the way it does. But knowing the key architectural decisions gives you a much clearer picture of its real strengths and limitations.
Mixture-of-Experts (MoE) Architecture
This is the foundational shift that separates Llama 4 from every previous Llama generation. In a traditional dense transformer model, every parameter is activated for every token processed. In a Mixture-of-Experts model, the input is routed to only a subset of “expert” sub-networks, meaning Llama 4 Maverick’s 400 billion total parameters activate only 17 billion for any given query.
Think of it this way: instead of every specialist in an organization weighing in on every decision, only the most relevant specialists are called into the conversation. The result is the knowledge capacity of a much larger model at the computational cost of a much smaller one.
Concretely, this means Maverick achieves frontier-adjacent performance while costing approximately $0.19 per million tokens blended on distributed inference, a fraction of what closed models charge for equivalent capability. Furthermore, Scout fits on a single H100 GPU despite having 109 billion total parameters, hardware accessibility that would be impossible with a dense architecture at comparable capability levels.
Native Multimodality via Early Fusion
Previous approaches to multimodal AI typically involved training a language model first, then adding vision capabilities as a separate module, a process called late fusion. Llama 4 uses early fusion: visual and language understanding were integrated from the beginning of training rather than added afterward.
Both Scout and Maverick were trained on large amounts of unlabeled text, image, and video data simultaneously, giving them a broad visual understanding that is architecturally embedded rather than bolted on. Consequently, Llama 4 can process a photograph and a paragraph of text in the same context window, enabling genuine cross-modal reasoning rather than just side-by-side processing.
Training Scale and Data
Both Scout and Maverick were trained on up to 40 trillion tokens, covering 200 languages with fine-tuning support for 12. MetaP hyperparameter scaling was used to optimize training across dimensions.
FP8 precision training enabled 10x speed gains over Llama 3’s training process. Additionally, the novel co-distillation approach, where Behemoth served as a teacher model during Scout and Maverick’s training, transferred frontier-level understanding into models deployable on accessible hardware. That codistillation is why Maverick outperforms what a purely 17-billion-active-parameter model should theoretically achieve.
Safety Infrastructure
Meta introduced a dedicated safety toolkit alongside Llama 4: Llama Guard for detecting unsafe inputs and outputs, Prompt Guard for identifying adversarial prompt injection attempts, and CyberSecEval for security evaluation. Additionally, Generative Offensive Agent Testing (GOAT) enables automated red-teaming.
Notably, Meta says it tuned Llama 4 models to refuse “contentious” questions less often than previous versions, a design choice that reflects a different approach to safety from Anthropic’s more conservative framework. That’s neither inherently right nor wrong, but it’s a meaningful philosophical distinction to understand before deploying Llama 4 in consumer-facing applications.
Benchmark Performance: How Does Llama 4 Stack Up?
Let me give you the honest benchmark picture, including the controversies, not just the highlights.
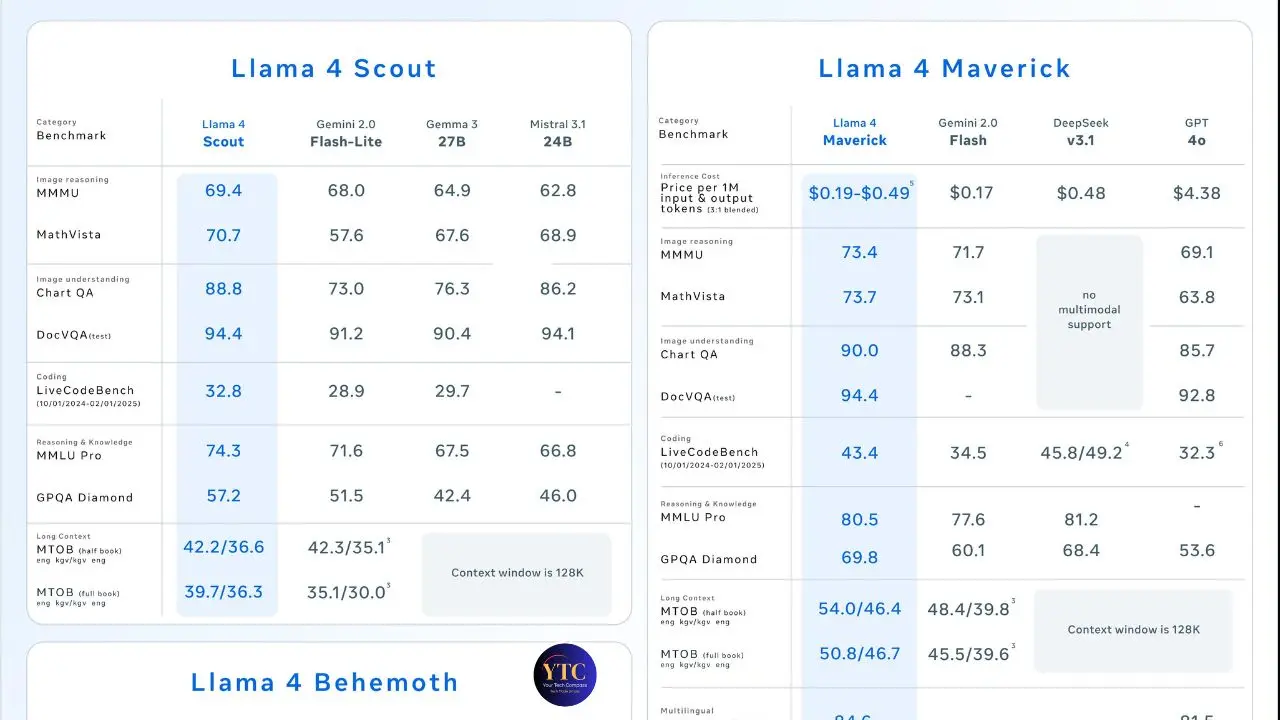
Maverick’s strongest results come from multimodal and reasoning tasks. Therefore, on:
- MMLU Pro (harder academic reasoning), Maverick scores 80.5%, meaningfully ahead of Llama 3.1, 405B’s 74.3% and competitive with leading closed models.
- LiveCodeBench (real-world coding), Maverick scores 43.4% versus 32.8% for Scout; both representing meaningful improvements over the Llama 3 family.
- Multilingual MMLU, Maverick scores 84.6%, reflecting the 200-language training coverage.
- Multimodal benchmarks, Maverick scores 73.4% on MMMU (image reasoning) and 90% on ChartQA (chart understanding), genuinely strong multimodal numbers for an open-weight model.
Scout’s standout is context handling. On MTOB (long-context machine translation involving half- and full-book-length texts), Scout substantially outperforms all comparable open-weight models, a direct reflection of its 10M-token context window and the architecture optimizations that make that context practically usable.
The honest caveats matter here. Meta faced scrutiny for submitting tuned experimental versions to public leaderboards, particularly on the LMSYS Chatbot Arena, that differed from publicly released weights.
Maverick reportedly appeared in the arena under a different name before formal release, raising legitimate reproducibility questions. Additionally, none of the Llama 4 models is a proper “reasoning” model in the style of OpenAI’s o1 or o3-mini; they don’t employ chain-of-thought self-verification at inference time. Consequently, on tasks that specifically reward extended deliberative reasoning, Llama 4 trails dedicated reasoning models regardless of raw parameter count.
Benchmark Comparison Table
Benchmark | Llama 4 Maverick | Llama 4 Scout | GPT-4o | Gemini 3.1 Pro | DeepSeek V4-Pro |
MMLU Pro | 80.5% | 74.3% | Competitive | Leading | Strong |
LiveCodeBench | 43.4% | 32.8% | N/A | N/A | 93.5% |
MMMU (Image Reasoning) | 73.4% | 69.4% | N/A | N/A | ❌ No vision |
ChartQA | 90% | 88.8% | N/A | N/A | ❌ No vision |
DocVQA | 94.4% | 94.4% | N/A | N/A | ❌ No vision |
Multilingual MMLU | 84.6% | N/A | N/A | 92.6% | N/A |
Context Window | 1M tokens | 10M tokens | 128K tokens | 1M tokens | 1M tokens |
Est. Inference Cost | ~$0.19/Mtok | Lower | ~$10+/Mtok | $12/Mtok | $3.48/Mtok |
Open-Weight | ✅ Yes | ✅ Yes | ❌ No | ❌ No | ✅ Yes |
Note: Benchmark scrutiny over tuned vs. released weights is a documented concern for Llama 4 Maverick. Always benchmark on your specific use case before production decisions.
How to Access and Run Llama 4: Your Practical Options
Here are all access paths, from zero-setup consumer interfaces to fully self-hosted infrastructure. Pick the one that fits your situation.
Meta AI (meta.ai): Zero Setup Required

The simplest entry point is meta.ai, Meta’s consumer-facing interface, available for free with no account required in most regions. Meta AI has been updated to use Llama 4 across WhatsApp, Messenger, Instagram, and Facebook in 40 countries.
You don’t choose which specific variant runs in the background. Meta routes traffic automatically. Consequently, this is the fastest way to experience Llama 4 with zero configuration, but it gives you no control over the model, your data, or the specific variant being used.
Hugging Face: Direct Weight Access
For developers who want the actual model weights, both Scout and Maverick are available on Hugging Face under the meta-llama organization, using the new Xet storage backend for faster downloads. Scout is available with on-the-fly int4 quantization for deployment on smaller hardware.
Maverick is available in BF16 and FP8 formats. The Llama 4 Community License Agreement applies; read it carefully if you’re building for commercial deployment, particularly regarding the EU restriction and the 700M MAU threshold.
Ollama: The Easiest Self-Hosting Path
For running Llama 4 locally on your own machine, Ollama remains the recommended starting point for non-infrastructure developers. Scout is the practical choice for local deployment; a single command pulls the model onto compatible hardware.
On an NVIDIA H100 80GB GPU, Scout runs cleanly in its standard precision format. Moreover, Ollama’s one-line installation and conversational interface make it accessible to developers seeking self-hosted AI without the infrastructure overhead of a full deployment pipeline.
Hardware requirements for local deployment:
- Llama 4 Scout (standard): Single NVIDIA H100 80GB GPU; int4 quantization enables smaller GPU options
- Llama 4 Scout (quantized): Can run on systems with 32–48GB VRAM with performance trade-offs
- Llama 4 Maverick: NVIDIA H100 DGX system or equivalent (8 x H100 GPUs recommended); FP8 format available
- Llama 4 Behemoth: Multi-node GPU cluster required; not yet publicly available
Meta’s Official Llama API

Meta offers its own hosted API at ai.meta.com, designed for developers who want API-level access to Llama 4 without the complexity of self-hosting. It follows a developer-first format compatible with standard API integration patterns. Additionally, managed inference providers like Groq, Together AI, and Fireworks AI offer Llama 4 access at per-token rates, often with faster inference than self-hosting on equivalent hardware, due to optimized inference infrastructure.
Major Cloud Marketplaces
AWS SageMaker JumpStart, Azure AI Studio, and Google Cloud Vertex AI all offer Llama 4 models through their model marketplaces. If your infrastructure already runs on one of these platforms, this is the lowest-friction path to deploying Llama 4 in production, with enterprise security, compliance controls, and support agreements already in place.
Real-World Use Cases: What You Can Actually Build With Llama 4
Here’s where Llama 4 stops being an architectural discussion and starts being a practical tool. These are the use cases where it genuinely outperforms alternatives, not on benchmarks, but on the real requirements of production applications.
Privacy-First AI Applications
When you deploy Llama 4 on your own infrastructure, no data leaves your environment. Your queries don’t pass through OpenAI’s servers. And your documents aren’t logged by Google. However, your customers’ information never touches a third-party cloud. Consequently, for healthcare providers handling patient records, law firms processing privileged communications, financial institutions managing proprietary data, and any application governed by data residency requirements, self-hosted Llama 4 is often the only compliant option.
The gap between “AI with your data” and “AI on your data” is one that only open-weight models can close. Furthermore, Maverick’s FP8 precision and Scout’s quantization options mean even regulated industries can deploy capable models on infrastructure they fully control.
Long-Context Document Analysis

Scout’s 10-million-token context window opens use cases that simply don’t exist for other available models. You can feed an entire multi-volume legal archive and ask cross-document questions in plain language. In addition, you can drop a full year of financial filings and ask for a comparative analysis.
You can process an entire software codebase, not just individual files, and ask architectural questions. Additionally, the MTOB benchmark results show that Scout genuinely utilizes that context rather than degrading on long sequences, as many models do. For any application where the value lies in reasoning across massive volumes of information, Scout has no open-weight peer.
Custom Fine-Tuning for Proprietary Use Cases
Because Llama 4’s weights are publicly available, you can fine-tune either Scout or Maverick on your own proprietary dataset, training the model to speak in your company’s voice, know your products, follow your specific policies, and perform tasks tailored to your industry. The Hugging Face ecosystem already hosts numerous community fine-tuned Llama 4 models. Moreover, fine-tuning techniques like LoRA (Low-Rank Adaptation) make it possible to fine-tune even Scout on accessible GPU hardware, dramatically reducing the cost of customization relative to what was possible with Llama 3’s larger dense models.
Cost-Efficient Production Inference at Scale
At volume, per-token API costs add up quickly. A product making 10 million API calls per day at $10 per million output tokens costs $100,000 per month in model inference alone.
Self-hosted Llama 4 replaces that cost with infrastructure spend that is typically a fraction of the API cost at meaningful volume. Additionally, Maverick’s estimated $0.19 per million tokens blended on distributed inference makes managed API access dramatically cheaper than GPT-4o or Claude-class models for equivalent workloads.
African Tech and Emerging Market Applications
This dimension deserves direct attention because Llama 4’s characteristics align specifically well with the constraints of African AI development. As covered in our AI in Africa guide and our Africa vs. India AI adoption analysis, African developers building AI applications face API cost constraints that make per-token pricing a genuine barrier.
Llama 4 Scout, deployable on a single H100 with quantization options for smaller hardware, changes that equation. Furthermore, Maverick’s 84.6% Multilingual MMLU score and training across 200 languages directly benefit developers building for non-English-speaking African populations. Zero-license-fee deployment, multilingual support and efficient architecture are the combination African AI developers need most.
Llama 4 vs The Competition: Honest Head-to-Head
Here are the four comparisons that most Llama 4 users are considering.
Llama 4 vs ChatGPT (GPT-4o / GPT-5.x)

On multimodal benchmarks where both compete, Llama 4 Maverick performs competitively, exceeding GPT-4o on certain coding, reasoning, multilingual, long-context, and image benchmarks according to Meta’s internal testing. However, more recent GPT-5.x models have pushed the frontier further, and Maverick doesn’t yet match the latest closed-source frontier across all dimensions.
Cost is the decisive factor: self-hosted Llama 4 is free, whereas GPT API costs add up at scale. Control is the second: Llama on your own infrastructure means zero data exposure. GPT-4o’s consumer UX, plugin ecosystem, and brand familiarity remain practical advantages for teams without infrastructure capacity.
The Honest Verdict: Llama 4 for cost, privacy, and customization; ChatGPT for consumer polish and zero-setup deployment.
Llama 4 vs Claude Opus 4.6 (Anthropic)
Claude leads Llama 4 in writing quality, structured planning output, and instruction-following consistency, advantages explored in depth in our Claude Opus 4.6 review. The decisive difference in deployment: Claude has no open-weight version.
You cannot run Claude locally, fine-tune its weights, or self-host it for data sovereignty. Llama 4 Maverick’s 1M-token context window matches Claude’s. Scout’s 10M token context significantly exceeds it. At $75 per million output tokens for Claude Opus 4.6 versus $0.19 per million output tokens for Maverick on distributed inference, the cost gap is extraordinary.
The Honest Verdict: Claude for enterprise polished output and safety-conscious deployments where API access is acceptable; Llama 4 for self-hosting, fine-tuning, and cost efficiency at scale.
Llama 4 vs Gemini 3.1 Pro
Gemini 3.1 Pro leads on abstract reasoning benchmarks (77.1% ARC-AGI-2), graduate-level science (94.3% GPQA Diamond; the highest ever recorded), and Google ecosystem integration, all covered in our Gemini 3.1 Pro review. Llama 4 wins on open availability, infrastructure independence, cost, Scout’s 10M token context window versus Gemini’s 1M, and the ability to deploy entirely outside Google’s cloud.
The Honest Verdict: Gemini for Google-integrated workflows and benchmark-leading reasoning; Llama 4 for infrastructure independence, self-hosting, and maximum deployment flexibility.
Llama 4 vs DeepSeek V4-Pro

Both are open-weight models; the most important shared characteristic. DeepSeek V4-Pro leads Llama 4 on pure coding benchmarks (LiveCodeBench: 93.5% vs. 43.4% for Maverick) and offers a similar 1M-token context window.
The critical difference is geopolitical and trust-related: DeepSeek’s hosted API routes through Chinese servers and has documented content restrictions on politically sensitive topics, as covered in our DeepSeek V4 review. Llama 4 is a US-developed model with no equivalent content-restriction concerns and a Community License, making it safer for Western enterprise deployment. Furthermore, Llama 4’s native multimodality (images and video) is absent from DeepSeek V4, which remains text-only.
The Honest Verdict: DeepSeek for maximum coding performance at low cost, where data residency concerns are addressed via self-hosting; Llama 4 for Western enterprise trust requirements and multimodal capability.
Head-to-Head Summary Table
Criteria | Llama 4 Maverick | GPT-4o | Claude Opus 4.6 | Gemini 3.1 Pro | DeepSeek V4-Pro |
Open-Weight Availability | ✅ Yes | ❌ No | ❌ No | ❌ No | ✅ Yes |
Self-Hosting Possible | ✅ Yes | ❌ No | ❌ No | ❌ No | ✅ Yes |
Fine-Tuning On Own Data | ✅ Yes | ❌ No | ❌ No | ❌ No | ✅ Yes |
API Output Cost (est.) | ~$0.19/Mtok | ~$10+/Mtok | $75/Mtok | $12/Mtok | $3.48/Mtok |
Multimodal Input | ✅ Text + image | ✅ Text + image | ✅ Text + image | ✅ Text + image + video | ❌ Text only |
Context Window | 1M (Maverick) / 10M (Scout) | 128K | 200K | 1M | 1M |
Data Sovereignty | ✅ Full (self-hosted) | ❌ OpenAI cloud | ❌ Anthropic cloud | ⚠️ Google Cloud | ⚠️ China-hosted API |
Content Restrictions | None (open weights) | Moderate | Moderate | Moderate | ⚠️ Documented |
Native Multimodality | Early fusion | Late fusion | Late fusion | Native | ❌ No |
Reasoning Model Support | ❌ No | ✅ o-series | ❌ No | ❌ No | ✅ Thinking mode |
Llama 4 Limitations: The Honest Assessment

Llama 4 has real limitations, and naming them directly is the most useful thing I can do for you.
No Dedicated Reasoning Mode
None of the Llama 4 models is a proper reasoning model in the style of OpenAI’s o1 or o3-mini. They don’t exhibit extended chains of thought or self-verification in their inferences.
Therefore, for tasks that specifically reward deliberative, step-by-step reasoning, complex math proofs, multi-step logical deductions, or scientific problem solving, Llama 4 trails dedicated reasoning models regardless of parameter count. Meta has signaled this is an area of active development, but it’s a real gap in the current release.
Benchmarking Controversy
The LMSYS Chatbot Arena submission controversy, in which a tuned experimental version of Maverick appeared under a different name before its formal release, raised legitimate questions about reproducibility between benchmarked and deployed model weights. Consequently, always benchmark Llama 4 on your specific use case rather than relying solely on published headline numbers.
EU Restriction
EU-domiciled users and companies are currently prohibited from using or distributing Llama 4 under the Community License Agreement. This is a significant, non-trivial limitation for European developers and businesses, and one that may or may not be resolved by future licensing updates.
Maverick Requires Serious Hardware for Self-Hosting
While Scout fits on a single H100, Maverick requires an H100 DGX system or equivalent. Therefore, for most individual developers and small teams, self-hosting Maverick is not practically accessible; managed inference via API is the realistic path. Additionally, Behemoth’s multi-node cluster requirements will place it outside the reach of all but the largest research operations when it eventually releases.
No Dedicated Web Search or Live Data
Like all base Llama models, Llama 4 has no native web browsing or real-time data access. For applications requiring current information, RAG (Retrieval-Augmented Generation) integration is a necessary additional engineering layer, not optional.
Community Fine-Tune Quality Is Uneven
The Hugging Face ecosystem has already produced numerous Llama 4 fine-tunes, some genuinely excellent, others that degrade capability or strip safety guardrails. Evaluating community fine-tuning requires judgment and testing. There is no centralized quality control equivalent to a commercial API.
For a broader look at how the full AI tools landscape is evolving, including models that complement Llama 4 in specific use cases, our AI Unboxed category covers the most relevant current options in depth. In addition, for developers and tech writers looking to publish guest articles and reach a wider tech audience, TechTalksToday is an active platform covering technology, business, and programming.
The Future of Llama 4: What Meta Is Building Toward

The April 2025 release was explicitly described by Meta as “just the beginning” for the Llama 4 collection. Here’s what’s on the horizon.
- Behemoth’s public release is the most anticipated event in the open-weight AI ecosystem. When Meta makes the 2-trillion-parameter model available (no timeline confirmed as of early 2026), it will be the largest open-weight model ever publicly released. Its internal STEM benchmark results already put it ahead of GPT-4.5, Claude 3.7 Sonnet, and Gemini 2.0 Pro. Furthermore, the distillation relationship between Behemoth and the Scout/Maverick pair means any improvements to Behemoth could flow into future Scout and Maverick iterations, creating a compounding capability pipeline.
- Reasoning model capabilities are the gap Meta has acknowledged and is working to close. Llama 4’s current models don’t employ inference-time chain-of-thought verification. A future reasoning-focused Llama 4 variant (analogous to what OpenAI has done with the o-series) would address the most significant current capability gap and make Llama 4 competitive across every category simultaneously.
- EU availability is a licensing and regulatory resolution that, if achieved, would dramatically expand Llama 4’s addressable developer community. The EU AI Act’s interaction with open-weight model licensing is an unresolved area, and one that Meta has a financial incentive to resolve.
- The Meta AI platform integration, rolling out Llama 4 across WhatsApp, Messenger, Instagram, and Facebook in 40 countries, gives Meta’s models a deployment-scale advantage that no other open-source model can match. As that integration deepens, the feedback loop between deployed user behavior and model improvement will accelerate in ways that pure research lab models cannot replicate. Moreover, the community fine-tuning ecosystem on Hugging Face continues producing specialized variants, from domain-specific healthcare models to language-specific fine-tunes, that collectively expand what the Llama 4 foundation can do.
FAQs
Yes, for most use cases. The Llama 4 Community License Agreement permits free commercial deployment for organizations with under 700 million monthly active users. EU-domiciled users are currently restricted under the current license terms. The weights are freely available for download from Hugging Face and Meta’s official channels. Running Llama 4 locally via Ollama or other self-hosting tools incurs no licensing costs, only the infrastructure costs of the required hardware or cloud compute.
On multimodal benchmarks and certain reasoning tasks, Llama 4 Maverick performs competitively with GPT-4o. The decisive advantages lie outside raw capability: Llama 4 is free to self-host, keeps your data on your own infrastructure, and can be fine-tuned on proprietary datasets, none of which is possible with ChatGPT. ChatGPT leads on consumer UX, plugin ecosystem depth, and zero-setup deployment. Consequently, the right choice depends on your priorities: Llama 4 for cost, privacy, and customization; ChatGPT for consumer polish and managed convenience.
Scout can be self-hosted on a single NVIDIA H100 80GB GPU in standard precision, or on smaller hardware using int4 quantization with some performance trade-off. Maverick requires an H100 DGX system or equivalent (8 x H100 GPUs), making it inaccessible for most individual developers without data center access. For developers on consumer hardware, managed API access via Groq, Together AI, or the official Llama API is the more practical path to Maverick-class capability. Ollama supports Scout deployment for accessible local experimentation.
Final Thoughts

Llama 4 is the most consequential open-weight AI release of 2025, and the most honest challenge yet to the assumption that frontier AI must be closed, expensive, and owned by a handful of San Francisco companies. Scout’s 10-million-token context window redefined what open models can achieve. Maverick’s combination of 400 billion total parameters, native multimodality, an early-fusion architecture, and a $0.19-per-million-token inference cost made the cost-performance case for open-weight AI impossible to dismiss. Furthermore, Behemoth’s eventual release, distilled from nearly 2 trillion parameters and already demonstrating STEM benchmark results that are competitive with the best closed models, signals that the capability ceiling for open-weight AI has not yet been reached.
The limitations are real and worth naming again: no dedicated reasoning mode, the EU license restriction, the benchmarking controversy, and Maverick’s hardware requirements for self-hosting. These are genuine constraints that affect real deployment decisions. But the trajectory is unmistakable. Llama 4 proves that open-weight AI can be multimodal, frontier-adjacent, and accessible on a single GPU simultaneously, and that the open ecosystem building on its foundation will produce specialized, fine-tuned, and improved variants faster than any single closed-source lab can replicate. The question for anyone building with AI in 2025 and beyond is no longer whether open-weight models are serious. Llama 4 settled that question on April 5, 2025.
The open-source AI revolution is moving faster than most people realize, and the decisions you make about your AI stack today will determine your flexibility tomorrow. Head over to YourTechCompass.com for the latest model reviews, comparisons, and practical guides that keep you ahead of the curve.