
I’ve been following Google’s AI model releases long enough to know the pattern. A big announcement, some impressive benchmark numbers, and then real-world performance that sometimes matches the slides and sometimes doesn’t. Gemini 3.1 Pro, released in preview on February 19, 2026, feels different, and not just because of the numbers. The ARC-AGI-2 score of 77.1%, more than double what Gemini 3 Pro achieved three months earlier, isn’t just a benchmark milestone. It’s a signal that Google DeepMind has made a genuine architectural leap in core reasoning, not just a fine-tuning pass. Add a 94.3% score on GPQA Diamond, the highest ever recorded on that graduate-level science benchmark, and you have the most credible challenge Google has mounted to OpenAI and Anthropic’s frontier positions in the three years of this AI race.
That said, benchmark leadership and real-world usefulness are different things, and I’ve been careful to separate them in this review. This is for you if you’re a developer deciding whether to rebuild your AI stack around Gemini, a business owner evaluating Google Workspace AI features, a researcher who needs the longest context window available, or simply someone who wants to understand whether Google’s flagship model finally justifies switching from whatever you’re using today. I’ve researched the architecture, tested the benchmarks against independent evaluations, and compared the honest trade-offs across every major competitor. What follows is my most detailed, most grounded assessment of where Gemini 3.1 Pro stands, and exactly who it’s worth it for.
Before we get into it: this review is independent. No brand paid for coverage, and no score was negotiated. If you want to see exactly how we evaluate tools: what we test, how we score, and how we handle affiliate relationships, our Review Methodology has all of it.
What Is Gemini 3.1 Pro and Where Does It Fit?
Gemini 3.1 Pro is Google DeepMind’s current flagship AI model; the most advanced model in the Gemini 3 series as of this review, designed for complex everyday reasoning, coding, multimodal analysis, and agentic task execution. To understand where it sits, you need the full lineage.
Gemini 1.0 launched in December 2023 as Google’s first true multimodal LLM; the opening bid in the direct competition with GPT-4. However, Gemini 1.5 Pro followed in February 2024 with a breakthrough 1-million-token context window that no competitor could match at the time. And, Gemini 2.0 Pro arrived in February 2025 with agentic capabilities and real-time multimodal processing.
Gemini 2.5 Pro in March 2025 was a thinking model that temporarily topped coding benchmarks and held the LMArena leaderboard position for a period. In addition, Gemini 3 Pro launched in November 2025, a new model generation with an architectural overhaul, stronger reasoning foundations, and expanded modality support. Gemini 3.1 Pro is the upgraded core intelligence in the Gemini 3 series, released on February 19, 2026, with substantially improved reasoning, stronger agentic performance, and expanded coding output features.
The key architectural context is native multimodality, not retrofitted. Gemini 3.1 Pro was trained simultaneously on text, images, audio, video, and code, not a language model with vision tacked on. Furthermore, it introduces MEDIUM as a thinking level parameter for developers, giving you more granular control over the cost-performance-speed trade-off in production.
For a broader look at how Gemini AI works architecturally, our Gemini AI explainer provides essential context.
Key Features: What Gemini 3.1 Pro Actually Does
Let me walk you through the features that actually matter, with a real-world implication for each one, not just a spec list.
Native Multimodality: Text, Images, Audio, Video, and Code
Gemini 3.1 Pro can comprehend vast datasets and challenging problems from massively multimodal information sources, including text, audio, images, video, and entire code repositories. That means you can feed it a video and ask for a summary, upload a scanned document and ask for data extraction, or combine audio transcripts with spreadsheet data in a single session.
Consequently, the range of workflows it can handle without switching tools is meaningfully wider than any pure text model. The model supports text, image, speech, and video input and outputs text, with image generation available via Imagen integration in specific product surfaces.
1-Million-Token Context Window
The 1M-token context window (approximately 750,000 words) is standard across Gemini 3.1 Pro access tiers, not a premium add-on. That’s enough to process an entire codebase, a full year of financial reports, a lengthy legal document corpus, or a multi-book research archive in a single session. Additionally, Gemini 3.1 Pro introduces improved token efficiency compared to 3 Pro; more efficient thinking across various use cases means you’re processing more intelligently, not just processing more.
Reasoning and Deep Thinking
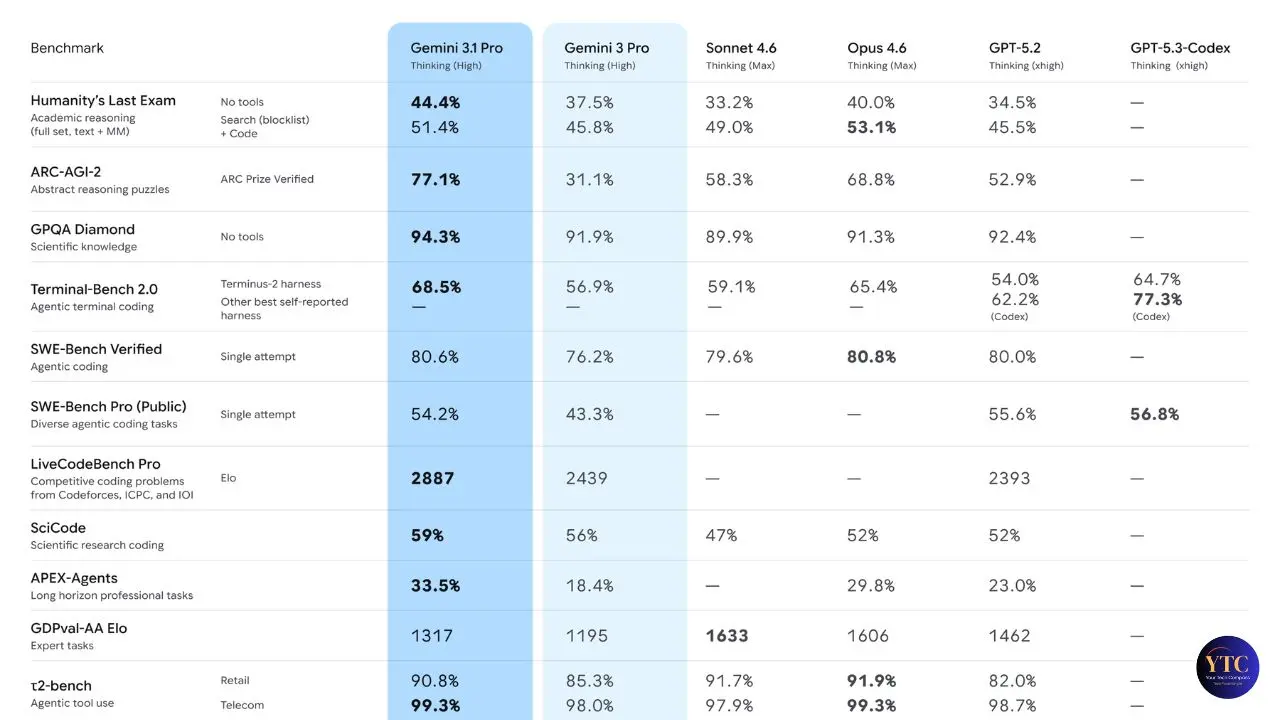
The most significant improvement in Gemini 3.1 Pro is its reasoning capability, and the ARC-AGI-2 benchmark clearly tells that story. ARC-AGI-2 tests a model’s ability to recognize entirely novel logic patterns that cannot be memorized during training. Scoring 77.1% versus Gemini 3 Pro’s 31.1%, more than double the performance, signals a genuine qualitative shift in how the model approaches problems it has never seen before.
Deep Think, which powered Gemini 3’s ability to disprove a decade-old mathematics conjecture, has now been distilled into 3.1 Pro for everyday use. You now get that reasoning quality on a standard Google AI Pro subscription, not just an Ultra plan.
Google Ecosystem Integration

This is Gemini 3.1 Pro’s most durable competitive advantage, and the one that matters most if you live and work inside Google’s stack. Native integration covers Google Workspace (Docs, Sheets, Gmail, Drive), Google Search grounding for real-time web-backed answers, YouTube video understanding, NotebookLM (now with 3.1 Pro for Pro and Ultra users), Google Cloud, Vertex AI, Gemini CLI, Android Studio, and Google Antigravity. Furthermore, Search grounding dramatically reduces hallucination on factual queries; Gemini 3.1 Pro ranked first in AA-Omniscience (hallucination reduction) in Artificial Analysis’s independent evaluation, ahead of every competitor in the benchmark set.
Agentic Capabilities (Doubled From 3 Pro)
Gemini 3.1 Pro’s agentic capabilities (its ability to autonomously plan, execute multi-step tasks, use tools, and self-correct) have roughly doubled compared to Gemini 3 Pro. It now leads GPT-5.2 and Claude across most agentic benchmarks, making it the preferred model for developers building autonomous AI workflows, coding agents, and production pipelines.
On Terminal-Bench 2.0, it jumped from 68.5% to 80.1%, an impressive 11.6-point gain measuring real-time command-line agent performance. Additionally, a dedicated endpoint (gemini-3.1-pro-preview-customtools) is available for developers building with custom tools and bash, specifically optimized for agentic workflows.
Code Generation and Execution
Gemini 3.1 Pro includes improved software engineering practices and usability, with agentic enhancements across domains such as finance and spreadsheet applications. It can also generate website-ready, animated SVGs directly from a text prompt, a new code-based animation capability introduced with 3.1.
It supports 20+ programming languages and can run code in a sandbox environment. Moreover, real-world developer feedback confirmed a meaningful improvement over Gemini 3 Pro, specifically on code refactoring. The new model “listens to system prompts reliably, avoids unnecessary verbosity in simple tasks, and handles complex code refactoring significantly more cleanly,” according to a widely cited Day 1 developer review.
Multilingual Performance
On the MMMLU benchmark (multilingual question answering), Gemini 3.1 Pro scored 92.6%, leading Gemini 3 Pro (91.8%), Claude Opus 4.6 (91.1%), and GPT-5.2 (89.6%). Consequently, for multilingual research, global business applications, and non-English content workflows, Gemini 3.1 Pro is the strongest broad-coverage model currently available. This is directly relevant for African markets, multilingual businesses, and any research context involving non-English source material.
Benchmark Performance: How Does It Actually Stack Up?
Let me give you the honest benchmark picture, including the parts Google’s own comparison table conveniently skips.
The headline results are genuinely strong. Gemini 3.1 Pro leads on 13 of 16 of the most important benchmark tests, including those related to abstract reasoning, agentic tasks, and graduate-level science. The 94.3% on GPQA Diamond is the highest score ever recorded on that graduate-level science benchmark, surpassing GPT-5.4’s 92.8% and every iteration of Claude.
On the Artificial Analysis Intelligence Index (a composite benchmark evaluating models across reasoning, knowledge, mathematics, and coding), Gemini 3.1 Pro scores 57, taking the Index’s top spot, 4 points ahead of Claude Opus 4.6 (53). It ranked first in 6 of 10 evaluation categories: Terminal-Bench Hard, AA-Omniscience, HLE, GPQA Diamond, SciCode, and CritPt (research-level physics reasoning).
However, the honest benchmark picture is more nuanced than “13 out of 16 wins” suggests. GPT-5.3-Codex had scores published for only 2 of 16 benchmarks, meaning Gemini wins by default in 14 categories against an absent competitor. Additionally, on GDPval-AA (enterprise task performance), independent data shows Claude models leading by over 300 points, a gap that matters significantly for finance, legal, and complex planning applications.
Furthermore, MMMU-Pro (multimodal understanding) shows that Gemini 3 Pro (81.0%) outperforms Gemini 3.1 Pro (80.5%), a reminder that newer models don’t always surpass predecessors across every dimension. Arena’s blind user voting also shows Claude Opus at 4.6, just 4 points ahead of Gemini 3.1 Pro in user preference ratings, a meaningful nuance given that Google’s own marketing implies more decisive leadership.
Full Benchmark Comparison Table
Benchmark | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.4 | DeepSeek V4-Pro |
ARC-AGI-2 (Abstract Reasoning) | 77.1% | N/A (unpublished) | N/A | N/A |
GPQA Diamond (Graduate Science) | 94.3% | N/A | 92.8% | 37.7% (HLE) |
MMMLU (Multilingual QA) | 92.6% | 91.1% | 89.6% | N/A |
Terminal-Bench 2.0 (Agentic) | 80.1% | 65.4% | 75.1% | 67.9% |
SWE-Bench Verified (Coding) | 80.6% | 80.8% | N/A | 80.6% |
Artificial Analysis Index | 57 | 53 | N/A | N/A |
GDPval-AA (Enterprise Tasks) | Below Claude | Leads by 300+ pts | N/A | N/A |
MMMU-Pro (Multimodal Understanding) | 80.5% | N/A | N/A | N/A |
HMMT 2026 (Math) | N/A | 96.2% | 97.7% | 95.2% |
HLE (Expert Cross-Domain Reasoning) | 44.4% | 40.0% | 39.8% | 37.7% |
Note: N/A indicates benchmark not published by that vendor. Benchmark conditions vary. Therefore, always verify use-case-specific results before selecting a model.
The honest takeaway: Gemini 3.1 Pro is the strongest model available right now for abstract reasoning, scientific knowledge, and factual retrieval at scale. It trails Claude on enterprise planning tasks and nuanced writing. Its advantage over GPT-5.4 is real, but partial; GPT leads in specific autonomous coding pipelines and computer-use tasks.
Pricing and Access: What You’ll Actually Pay

Gemini 3.1 Pro is accessible through several channels at different price points. Here’s the honest breakdown.
Free Tier (Google AI Studio)
You can access Gemini 3.1 Pro in preview through Google AI Studio with rate limits applied. This is the fastest way to evaluate the model without incurring any cost, and the rate limits are generous enough for meaningful testing.
Gemini App (Google AI Pro Plan)
Available on the Google AI Pro subscription at $19.99 per month, which also covers NotebookLM Pro access. Google AI Ultra (a higher-tier) offers the broadest access limits and priority availability during the preview rollout. Google’s plan mapping is not yet published as a simple “plan X = model Y” chart, but 3.1 Pro is rolling out across AI Pro and Ultra as the primary model.
Gemini API (AI Studio / Vertex AI)
$2.00 per million input tokens and $12.00 per million output tokens for Gemini 3.1 Pro Preview, based on Google’s API pricing. This is somewhat higher than the average for comparable models; the Artificial Analysis median for similar-tier reasoning models is $1.50 input per $8.00 output. However, the pricing is unchanged from Gemini 3 Pro at the API level, meaning you’re getting dramatically more reasoning capability for the same cost.
Compared to the Competition
Claude Opus 4.6 costs $15.00 per million input tokens and $75.00 per million output tokens, more than 6x Gemini’s output cost. Gemini 3.1 Pro is less than half the cost of Opus 4.6 for an equivalent inference volume, according to independent cost comparisons from Artificial Analysis.
Consequently, for developers making high-volume API calls, that cost differential has a direct and significant impact on total infrastructure spend. DeepSeek V4-Pro is cheaper still at $1.74 input / $3.48 output, but is a closed-weight model on foreign-hosted servers with documented content restrictions, as covered in our DeepSeek V4 review.
Vertex AI Enterprise
Custom pricing for large-scale enterprise deployment on Google Cloud, with additional security, compliance controls, and dedicated support.
Gemini 3.1 Pro vs The Competition: Honest Head-to-Head
Here’s the direct comparison across the four models most buyers are choosing between in 2026.
Gemini 3.1 Pro vs GPT-5.4 (OpenAI)

Gemini 3.1 Pro leads on abstract reasoning (ARC-AGI-2: 77.1% vs. unpublished for GPT), graduate-level science (GPQA Diamond: 94.3% vs. 92.8%), and agentic terminal tasks (Terminal-Bench 2.0: 80.1% vs. 75.1%). GPT-5.4 leads on autonomous coding pipelines, computer-use tasks, and, critically, time-to-first-token latency.
Gemini 3.1 Pro’s 24–29-second TTFT is a real friction point for interactive applications, where GPT responds meaningfully faster. Furthermore, ChatGPT’s consumer ecosystem (broader plugin library, established user familiarity, and more mature mobile experience) remains a practical advantage for non-developer users.
The Honest Verdict: Gemini leads in reasoning and science; GPT leads in speed and consumer-ecosystem depth. Choose based on your primary use case.
Gemini 3.1 Pro vs Claude Opus 4.6 (Anthropic)
This is the most nuanced comparison in the current landscape. Gemini leads on ARC-AGI-2 abstract reasoning (Claude doesn’t publish this score), GPQA Diamond (94.3% vs. unpublished for Claude), and Terminal-Bench 2.0 agentic tasks (80.1% vs. 65.4%).
Claude leads on GDPval-AA enterprise task performance (300+ point gap), SWE-Bench Verified real-world software engineering (80.8% vs. 80.6%), and structured planning output, where Claude generates approximately 10x more tokens for complex planning documents than Gemini in identical tests. Moreover, Claude’s instruction following is more consistent in interactive use, and its safety and transparency framework is more mature and publicly documented. You can explore our full breakdown of Claude Opus 4.6.
The Honest Verdict: Gemini for reasoning, science, and cost-efficient API usage at scale; Claude for enterprise planning, nuanced writing, and tasks requiring detailed, structured output.
Gemini 3.1 Pro vs DeepSeek V4-Pro
On pure benchmark performance, Gemini leads significantly. Gemini’s GPQA Diamond score of 94.3% dwarfs DeepSeek V4-Pro’s HLE score of 37.7%. These are different benchmarks, but the capability gap in scientific reasoning is real.
Gemini leads on agentic tasks (Terminal-Bench 2.0: 80.1% vs. 67.9%). DeepSeek V4-Pro leads on pure cost, $3.48 per million output tokens versus Gemini’s $12.00, and on open-weight availability under the MIT license. Additionally, DeepSeek’s data residency concerns (China-hosted servers) don’t apply to Gemini, which runs on Google’s global infrastructure with enterprise-grade privacy controls.
The Honest Verdict: Gemini is the stronger, safer model at a higher cost; DeepSeek is the cost-efficient alternative for coding-heavy workloads where data sovereignty concerns have been resolved through self-hosting.
Gemini 3.1 Pro vs Gemini 3 Pro (The Upgrade Question)

This is the question existing Gemini users need answered. The upgrade is meaningful, particularly if your work involves complex reasoning, agentic workflows, or coding. ARC-AGI-2 jumped from 31.1% to 77.1%, more than double.
Terminal-Bench 2.0 agentic performance jumped from 68.5% to 80.1%. Real-world developer feedback describes the improvement as “massive” on code refactoring and system prompt reliability. Furthermore, the output truncation issue that affected Gemini 3 Pro in production has been resolved. The model also introduces a MEDIUM thinking level for developers, offering a middle ground between full reasoning computation and instant response.
The Honest Verdict: If you use Gemini for complex reasoning, coding, or agentic tasks, this is a genuine and meaningful upgrade, not a minor iteration.
Full Head-to-Head Summary Table
Criteria | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.4 | DeepSeek V4-Pro |
Abstract Reasoning (ARC-AGI-2) | 77.1% | Unpublished | Unpublished | Unpublished |
Graduate Science (GPQA Diamond) | 94.3% | N/A | 92.8% | N/A |
Agentic Tasks (Terminal-Bench) | 80.1% | 65.4% | 75.1% | 67.9% |
Enterprise Planning Tasks | Behind Claude | Leads by 300+ pts | N/A | N/A |
Response Speed (TTFT) | ⚠️ 24–29s | Fast | Fastest | Fast |
Context Window | 1M tokens | 200K tokens | 128K tokens | 1M tokens |
API Output Cost (Per 1M Tokens) | $12.00 | $75.00 | ~$30.00 | $3.48 |
Google Ecosystem Integration | Native | None | None | None |
Multimodal Input | Text, image, audio, video | Text, image | Text, image | Text only |
Open-Weight Availability | ❌ No | ❌ No | ❌ No | ✅ Yes (MIT) |
Data Privacy | Google Cloud (enterprise controls) | Anthropic cloud | OpenAI cloud | ⚠️ China-hosted |
Real-World Use Cases: What Gemini 3.1 Pro Does Best (Who Benefits)
Here’s where Gemini 3.1 Pro stops being a benchmark discussion and starts being a practical tool. Let me show you who gets the most value from it.
Researchers and Analysts

The 1M-token context window, plus Search grounding, is a research stack in itself. You can feed entire academic paper collections, multi-year financial archives, or regulatory document libraries into a single session and query them in plain language.
Gemini 3.1 Pro’s AA-Omniscience first-place ranking for hallucination reduction; the best of any model independently evaluated, means the answers you get are more reliably backed by actual content rather than confabulated connections. Furthermore, for graduate-level scientific reasoning, a GPQA Diamond score of 94.3% isn’t just a number; it means the model is genuinely useful for serious science, not just science-flavored text generation.
Developers and Engineers
If you’re building on Google Cloud, Gemini 3.1 Pro is the obvious integration choice; it connects natively to every Google service without middleware. The new custom tools endpoint makes it particularly well-suited for complex agentic coding workflows that use custom Bash tools. Additionally, the resolved output truncation issue in Gemini 3 Pro means production deployments won’t encounter the unpredictable cutoffs that frustrated developers in the previous version.
For those building AI-powered productivity tools, such as the ones covered in our Clari Copilot vs. Saner.ai comparison, Gemini’s native Google Workspace integration eliminates the need for custom API bridging entirely.
Content Creators and Marketers
Google Workspace integration is the primary value here. If you’re writing in Google Docs, managing campaigns in Google Sheets, or analyzing performance data in Looker, Gemini 3.1 Pro is embedded directly into your existing workflow.
No API setup. No copy-pasting between tools.
Furthermore, YouTube video understanding (feeding a YouTube video into Gemini to request content angles, key quotes, or SEO hook ideas) is a workflow that no other frontier model supports natively. Code-based animation (generating website-ready, animated SVGs from a text prompt) is a new creative capability worth experimenting with for landing pages and visual content.
Business and Enterprise Users
Real-time Search grounding is the enterprise feature that justifies Gemini for business use cases where accuracy on current information matters. Legal research, competitive intelligence, financial reporting, and compliance analysis all benefit from AI that can anchor its responses in live, verified web data rather than training cutoff knowledge. Additionally, the broader Google Workspace Gemini for Business tier (available at per-seat pricing) brings 3.1 Pro’s intelligence directly into the tools enterprise teams already use without IT configuration overhead.
Education and Multilingual Applications
Gemini 3.1 Pro’s 92.6% on MMMLU puts it ahead of every competitor on multilingual question answering. For educators, students, and researchers working in non-English languages, including African languages, which are increasingly relevant as AI expands across the continent, as discussed in our Africa vs. India AI adoption analysis, Gemini’s multilingual strength is a practical differentiator. Moreover, NotebookLM (now powered by Gemini 3.1 Pro for Pro and Ultra users) is one of the most genuinely useful AI research tools available, allowing you to create interactive notebooks from PDFs, videos, and web sources with source-grounded AI responses.
Limitations and Honest Weaknesses

No credible review skips this section, and Gemini 3.1 Pro has real limitations worth naming directly.
The Latency Problem Is Real
A time-to-first-token of 24–29 seconds is at the higher end compared to other reasoning models; the median for comparable models is 2.75 seconds. That 10x latency gap matters enormously for interactive applications where you’re waiting for a response in real time.
For batch processing and research workflows, 29 seconds is irrelevant. However, for conversational use or customer-facing applications, it’s a friction point that competitors don’t share.
It’s Verbose
Gemini 3.1 Pro generated 57 million tokens during Artificial Analysis’s Intelligence Index evaluation, which was described as “somewhat verbose,” compared to the average of 35 million tokens. In production, this translates to longer responses, higher token costs, and outputs that sometimes need trimming. Consequently, for applications where conciseness matters (chatbots, summaries, quick answers), the verbosity needs to be managed via system prompt instructions.
Enterprise Planning Tasks Trail Claude Significantly
When asked to produce detailed, comprehensive planning documents, Gemini 3.1 Pro generates approximately 2,500 tokens compared to Claude Opus 4.6’s 25,000 tokens for the same complex task. A 10x output difference on planning-heavy workflows is not a minor gap. If structured, detailed enterprise planning is your primary use case, Claude holds a clear advantage.
Preview Status Means Instability
As of this review, Gemini 3.1 Pro is still in preview. Google has stated that general availability is coming “soon,” but preview models can exhibit changes in behavior, rate-limit fluctuations, and endpoint deprecations without advance notice. Build production dependencies carefully until GA is confirmed.
Full Power Requires a Google Ecosystem Commitment
Search Grounding, Workspace Integration, YouTube Understanding, and NotebookLM all deliver maximum value if you’re already operating within Google’s stack. If you’re primarily using Notion, Slack, Salesforce, and AWS, the ecosystem advantages that justify Gemini’s pricing don’t fully transfer.
Google’s Data Practices Deserve Attention
As with any Google product, your interactions with Gemini inside consumer-facing Google products contribute to Google’s data ecosystem. For enterprise use on Vertex AI with Google Cloud contracts, data processing terms are clearly defined. However, for individual and consumer-plan users, it is responsible to review Google’s AI data usage policy before processing sensitive information.
In addition, for a broader view of how the AI tool landscape is evolving, including tools that complement frontier models like Gemini, explore our AI Unboxed category.
Who Should Use Gemini 3.1 Pro
Use Gemini 3.1 Pro if you need the strongest available model for abstract reasoning, graduate-level scientific analysis, and hallucination-reduced factual research. It’s for you if you’re already in the Google ecosystem (Workspace, Cloud, YouTube, NotebookLM) and want AI that operates natively within your existing tools without the overhead of integration.
Furthermore, it’s for developers building on Google Cloud who want the most capable model with the deepest native service integrations. It’s for researchers who need a 1M-token context window in a stable, commercially available format. And it’s for anyone running high-volume API inference who needs Claude-class reasoning at less than one-fifth of Claude’s output cost.
Who Shouldn’t Use Gemini 3.1 Pro

Consider alternatives if you need the best pure writing quality, instruction following, and structured planning output; Claude Opus 4.6 leads here by a meaningful margin. Also, if you need the fastest response times for interactive or customer-facing applications, GPT-5.4’s latency advantage is significant.
In addition, if you’re budget-constrained and need frontier-class coding performance, DeepSeek V4-Pro at $3.48 per million output tokens is dramatically cheaper, though with the data residency and content restrictions documented in our full DeepSeek V4 review. And if you’re primarily outside the Google ecosystem with no plans to change, the integration advantages that differentiate Gemini 3.1 Pro from its competitors don’t fully apply to your workflow.
FAQs
Gemini 3.1 Pro is the upgraded core intelligence of the Gemini 3 series, released in preview on February 19, 2026. The primary differences are in reasoning quality and agentic performance. On ARC-AGI-2, Gemini 3.1 Pro scored 77.1% versus 31.1% for Gemini 3 Pro, more than double the reasoning performance in three months. On agentic benchmarks, improvements ranged from 45% to over 80% relative gains. Additionally, the output truncation issue that affected Gemini 3 Pro in production has been resolved, and a new MEDIUM thinking-level parameter gives developers more flexibility in cost-performance trade-offs.
On specific benchmarks, yes. Gemini 3.1 Pro leads on abstract reasoning, graduate-level science, and agentic terminal tasks. On speed, consumer ecosystem depth, and specific autonomous coding pipelines, GPT-5.4 leads. Gemini holds the top position on Artificial Analysis’s Intelligence Index, 4 points ahead of Claude Opus 4.6 and above GPT-5.2, but ChatGPT’s response latency is significantly faster, making it more practical for conversational applications. The honest answer is that Gemini 3.1 Pro is the stronger reasoning model; ChatGPT is the faster, more broadly accessible consumer experience.
Via the API, Gemini 3.1 Pro Preview costs $2.00 per million input tokens and $12.00 per million output tokens. The Gemini app is available on the Google AI Pro plan at $19.99 per month. Enterprise pricing via Vertex AI is custom. Compared to Claude Opus 4.6 at $15.00 input / $75.00 output per million tokens, Gemini is dramatically cheaper, less than half the cost for equivalent inference volume.
Conclusion

Gemini 3.1 Pro is the most credible challenge Google has mounted to frontier AI leadership, and it’s not a close call on the specific dimensions where it leads. A 77.1% ARC-AGI-2 score, 94.3% on GPQA Diamond (the highest ever recorded), first-place ranking on the Artificial Analysis Intelligence Index, and agentic capabilities that have doubled from Gemini 3 Pro represent a genuine leap in core intelligence, not a marketing iteration. Furthermore, at $12.00 per million output tokens, compared with Claude’s $75.00, the cost-to-capability ratio is the most competitive among closed-source frontier models currently available. For researchers, analysts, Google Cloud developers, and anyone who needs the longest context window with the strongest hallucination controls, Gemini 3.1 Pro earns serious consideration as a primary model in 2026.
The limitations are equally real, and I’ve been direct about them throughout this review. The 24–29-second time-to-first token is a genuine friction point for interactive applications. The enterprise planning gap relative to Claude is not marginal; a 10x output difference for structured planning tasks is a workflow-level distinction. The preview label means production deployments carry uncertainty until general availability is confirmed. And the full power of Gemini 3.1 Pro is primarily realized within Google’s ecosystem, which is a compelling reason to choose it if you’re there, but a limited incentive if you’re not. Google’s trajectory from Gemini 1.0 to 3.1 is arguably the fastest improvement arc of any major AI lab in the past three years. What comes after 3.1 Pro is the more interesting question.
The AI model landscape shifts fast, and staying ahead of those shifts is exactly what YourTechCompass is built for. Check out the latest model reviews, comparisons, and hands-on breakdowns that help you make smarter decisions about the tools you build and work with.


