
I’ll be honest with you, I went into this review with measured expectations. xAI has been the loudest entrant in the frontier AI race, but loudness and capability are different currencies. Grok 1 and 2 were interesting. Grok 3 was genuinely competitive. Then on July 9, 2025, xAI introduced Grok 4 through a livestream that drew roughly 1.5 million concurrent viewers. Elon Musk claimed the model “is smarter than almost all graduate students in all disciplines simultaneously,” and the AI community collectively leaned forward. The benchmark numbers that followed, particularly on Humanity’s Last Exam and graduate-level scientific reasoning, were exceptional enough to merit more than a marketing explanation. The question I set out to answer in this review is the one that actually matters: does Grok 4 translate exceptional benchmark performance into a tool worth building with, paying for, and reaching for over established alternatives?
This review is for you if you’re an X Premium subscriber wondering whether Grok 4 deserves serious attention beyond the social media hype, a developer evaluating the xAI API against OpenAI and Anthropic alternatives, a researcher trying to understand where the model genuinely leads versus where it follows, or anyone tracking the competitive AI model landscape as it stands heading into late 2025. I’ve researched the architecture, verified the benchmarks against independent evaluations, stress-tested the competitive comparisons, and named the limitations that xAI’s own marketing materials don’t emphasize. What follows is the complete, honest picture.
A note before we begin: every YTC score is earned, never negotiated. If you want to understand exactly how we evaluate apps & tools and how we handle affiliate relationships, our Review Methodology lays it all out.
What Is Grok 4 and Where Does xAI Fit in the AI Landscape?
xAI is Elon Musk’s artificial intelligence company, founded in July 2023 with a stated mission to “accelerate human scientific discovery.” It’s positioned as a counter-narrative to what Musk publicly describes as politically biased AI, a framing that shapes the model’s design philosophy, as you’ll read about later in this review.
To understand where Grok 4 sits, you need to understand its lineage. Grok 1 launched in November 2023 as xAI’s opening move, integrated into X (Twitter) with a deliberately irreverent personality. And Grok 1.5 improved reasoning and coding in March 2024.
Grok 2 arrived in August 2024 with multimodal capabilities and the Aurora image generation model. In addition, Grok 3, launched in February 2025, was a significant upgrade, introducing Think and DeepSearch modes and establishing Grok as a genuinely competitive model for the first time. Grok 3.5 followed in June 2025 with reasoning refinements and extended context.
Grok 4 arrived on July 9, 2025, built on version 6 of xAI’s foundation model, using 100x more training compute than Grok 2 and 10x more reinforcement learning compute than Grok 3. Furthermore, the Grok 4 family has continued to evolve post-launch: Grok 4.1 launched in November 2025 with improvements to emotional intelligence; Grok 4.3 arrived in May 2026 with dramatically improved agentic performance and significantly lower pricing.
The Funding Context Matters

xAI raised $6 billion in its Series C in 2024 and an additional $10 billion in May 2025, backed by a16z, BlackRock, Sequoia, and others, making it one of the best-capitalized AI labs in the world. Additionally, xAI announced that SpaceX has acquired xAI, thereby creating deeper integration between Musk’s companies and SpaceX’s compute resources. That capital, combined with SpaceX’s infrastructure relationships, gives xAI a compute runway that enables the kind of training scale Grok 4’s numbers reflect.
The Distinctive Advantage That No Other Lab Can Replicate
Grok has real-time access to X’s data firehose: live posts, trends, breaking news, and the full X social graph. Models with static training cutoffs answer present-day questions based on the past. Grok 4 can answer questions about events that happened an hour ago. Consequently, this real-time knowledge integration is not a minor feature; it’s a structural differentiation from every closed-source competitor.
Grok 4 Key Features: What’s New and What Actually Matters
Let me walk you through the features that change real workflows, not just the ones that look impressive in a demo.
Frontier Reasoning with Native Tool Use
Grok 4 was trained with reinforcement learning to use tools, a fundamentally different approach from models that treat tool use as a capability bolted onto an existing architecture. This means Grok 4 doesn’t just answer questions.
It chooses its own search queries, dives as deeply as needed into web results, runs code in a sandboxed environment, and synthesizes across multiple sources before responding. Furthermore, xAI introduced Grok 4 Heavy, a multi-agent tier in which several parallel agents collaborate per request, each checking the others’ reasoning. Internal tests showed a 5–8 percentage point lift in patch accuracy for code-intensive tasks when using the Heavy configuration.
Grok 4 also supports a standard thinking mode for complex multi-step problems, equivalent to OpenAI’s o-series chain-of-thought reasoning. In practice, the result for you is a model that handles scientific, mathematical, and multi-step analytical problems at a level that previous versions of Grok couldn’t reach. According to xAI’s technical documentation, the model achieves PhD-level performance across all academic disciplines simultaneously, a claim the HLE benchmark score partially substantiates.
Real-Time X Data Integration: The Unique Moat
This is Grok 4’s most defensible competitive advantage and the one you can’t get from any other model. Grok can use advanced keyword and semantic search tools and even view media from within X, searching posts, user profiles, and threads in real time to improve the quality of its answers. When you ask Grok 4 about a breaking news story, a viral post from last week, or a trending conversation happening right now, it can find, read, and reason about actual X content as soon as you ask.
Additionally, xAI has extended this with DeepSearch, a research mode that combines real-time web browsing with X data integration to produce research-grade summaries with source attribution. For competitive intelligence, trend analysis, social sentiment research, or understanding what’s actually being said about a topic across public discourse right now, this combination has no equivalent among closed-source competitors.
Honest Limitation: X’s data is not a neutral source of information. It reflects the platform’s demographic skew, algorithmic curation, and, as you’ll read in the limitations section, the editorial stance that has shaped Grok’s political behavior through 2025.
Multimodal Capability and Aurora Image Generation
Grok 4 accepts text, images, documents, and audio inputs. Aurora, xAI’s autoregressive image-generation model, is integrated to provide visual output.
Grok Imagine, launched in August 2025, extended this to text-to-video generation, producing 6-second clips with sound, smooth transitions, and image-to-animation conversion. Consequently, within a single Grok session, you can analyze an uploaded document, describe its contents, generate a related visual, and produce a short video asset, a creative workflow integration that most competitors require multiple tools to replicate.
Grok 4 Code: The Developer-Specific Variant
Released on July 11, 2025, Grok 4 Code is a coding-optimized variant built on the Grok 4 foundation. Key enhancements include support for 20+ programming languages, such as Python, Rust, TypeScript, and Swift; an integrated VS Code-style editor for inline refactoring and real-time debugging; and native X platform integration for repository management and deployment without switching tools. Furthermore, grok-code-fast-1, a speedy, economical reasoning model designed for agentic coding, was released in September 2025, giving developers a lower-latency option for coding pipelines.
Context Window and Speed
Grok 4 supports a 256,000-token context window, enough to process a full codebase, a lengthy legal document, or a comprehensive research archive in a single session. Regarding inference speed, Grok 4 generates approximately 42.5 tokens per second at the API level, below the median of 60.1 tokens per second for comparable reasoning models, according to Artificial Analysis.
Time to first token is approximately 19.86 seconds, on the higher end for the category. Consequently, Grok 4 is not the fastest model in its intelligence tier; it’s a deliberate trade-off between reasoning depth and response latency.
Benchmark Performance: The Numbers Behind the Claims
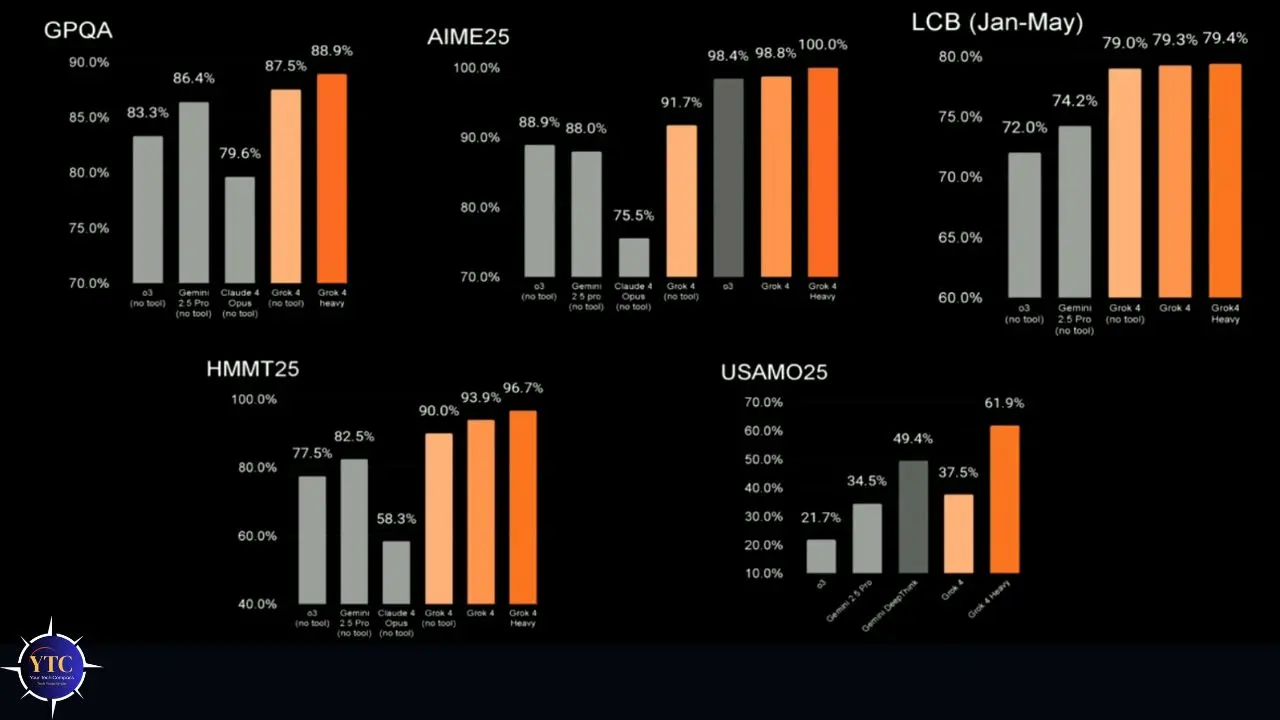
Let me give you the benchmark picture, honestly, including both what’s exceptional and what the independent data qualifies.
The headline numbers that drove the July 2025 launch conversation were Grok 4’s scores on Humanity’s Last Exam (HLE), a benchmark specifically designed to test AI on questions that stump human experts across academic disciplines. Grok 4 Heavy achieved a score of 44.4% on HLE, according to xAI’s official benchmark page, matching or exceeding Gemini 3.1 Pro’s 44.4% and ahead of Claude Opus 4.6 (40.0%) and GPT-5.4 (39.8%). On GPQA Diamond (graduate-level science), Grok 4 Heavy scored 87.5%, strong but below Gemini 3.1 Pro’s record-setting 94.3%.
Grok 4’s most distinctive strength lies in agentic, real-world task performance. On the AA Intelligence Index, a composite benchmark covering reasoning, knowledge, mathematics, and coding, standard Grok 4 scores 42, placing it above average for comparable reasoning models (median: 36).
Grok 4.3, the most recent iteration, pushed that score to 53 on the same index while significantly improving cost efficiency. Additionally, on GDPval-AA (enterprise task performance), Grok 4.3 scored an ELO of 1,500, a 321-point jump over its predecessor, surpassing Gemini 3.1 Pro, GPT-5.4 mini, and Kimi K2.5 on this metric.
The Honest Caveats the Benchmark Picture Requires
First, xAI published its own benchmarks, and many metrics derive from xAI’s internal evaluations or community leaderboards rather than peer-reviewed third-party benchmarks; independent coverage has consistently flagged this.
Second, Grok 4 is notably verbose: it generated 88 million tokens to run the Intelligence Index evaluations, compared to an average of 36 million for comparable models. That verbosity affects both cost and practical usability.
Third, Artificial Analysis independently rated Grok 4 as “above average in intelligence, but particularly expensive when compared to other models of similar price. It’s also slower than average and very verbose.” That’s an independent evaluation worth taking seriously.
Benchmark Comparison Table

Benchmark | Grok 4 / 4 Heavy | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro | DeepSeek V4-Pro |
HLE (Expert Reasoning) | 44.4% | 39.8% | 40.0% | 44.4% | 37.7% |
GPQA Diamond (Grad Science) | 87.5% | 92.8% | N/A | 94.3% | N/A |
AA Intelligence Index | 42 (standard) / 53 (4.3) | N/A | 53 | 57 | N/A |
GDPval-AA (Enterprise Tasks) | 1,500 ELO (4.3) | N/A | High | Competitive | N/A |
Context Window | 256K tokens | 128K tokens | 200K tokens | 1M tokens | 1M tokens |
Output Speed (Tokens/Sec) | 42.5 t/s | Faster | Faster | 123 t/s | Fast |
API Output Cost (Per 1M) | $21.25 (standard) / $2.50 (4.3) | ~$30 | $75 | $12 | $3.48 |
Real-Time X Data Access | ✅ Yes | ❌ No | ❌ No | ❌ No | ❌ No |
Open-Weight Availability | ❌ No | ❌ No | ❌ No | ❌ No | ✅ Yes |
Note: Grok 4.3 is the latest iteration, with significantly improved performance and pricing. Some xAI benchmark claims are from internal evaluations; independent third-party reproduction remains limited.
Pricing and Access: What You’ll Actually Pay
Grok 4’s pricing structure is more complex than most AI tools, because access is split across multiple subscription products with different feature gates. Let me map it out clearly.
- Free access via grok.com and X app: Basic Grok access with no payment required. Free users are limited to 2 prompts every 2 hours on Grok 4, a genuinely limited allocation for any serious use.
- X Premium ($8/month) and X Premium+ ($40/month): X Premium+ subscribers get higher Grok usage limits and priority access to Grok 4. This is the subscription structure where Grok access is bundled with X platform features, which is a genuine consideration if you don’t actually use X’s social features and resent paying for them alongside your AI tool.
- SuperGrok ($30/month): The dedicated Grok subscription that provides full Grok 4 access, including the standard thinking mode, DeepSearch, and significantly higher usage limits than X Premium tiers.
- SuperGrok Heavy ($300/month): The premium tier that unlocks Grok 4 Heavy, the multi-agent configuration that spawns parallel agents per request. At $300/month, this tier is well-suited to research labs, enterprise AI architects, and code-intensive development teams, where a 5–8 percentage-point accuracy lift on complex tasks justifies the cost.
- xAI API for Developers: Grok 4 standard is available at $4.25 per million input tokens and $21.25 per million output tokens. Grok 4.3, however, reduced those prices dramatically to $1.25 per million input tokens and $2.50 per million output tokens, representing a 37.5% reduction in input price and a 58.3% reduction in output price compared to its predecessor. Consequently, Grok 4.3 via API is now one of the more cost-competitive frontier-adjacent models available.
- xAI for Government and Enterprise: Custom pricing for large-scale enterprise deployment, launched in August 2025.
Grok 4 vs The Competition: Honest Head-to-Head
Let me give you the direct comparison across the four models most Grok 4 users are weighing alternatives against.
Grok 4 vs ChatGPT (GPT-5.4)

Both models claim frontier-reasoning positions, but the key differentiators are data and the ecosystem, not raw capability. On HLE, Grok 4 Heavy and GPT-5.4 trade blows (44.4% vs. 39.8%). On graduate-level science (GPQA Diamond), GPT-5.4 leads (92.8% vs. 87.5% for Grok 4). However, for real-time information, Grok 4 has no equivalent; X firehose access plus DeepSearch provides current knowledge that ChatGPT’s web search, while strong, doesn’t fully replicate for social trends and breaking news intelligence.
ChatGPT leads in consumer ecosystem depth, with maturity in plugins, memory, and image generation, and has the most established brand recognition of any AI product. Furthermore, GPT-5.4’s speed advantage is meaningful in interactive applications, where Grok 4’s 19-second TTFT results in noticeable latency. Our ChatGPT 5.4 breakdown covers GPT’s current capabilities in full.
The Honest Verdict: Grok 4 for real-time X-native research and trend analysis; ChatGPT for consumer polish, ecosystem breadth, and interactive speed.
Grok 4 vs Claude Opus 4.6 (Anthropic)
Claude Opus 4.6 leads Grok 4 on structured enterprise planning tasks, nuanced writing quality, and instruction-following consistency, as covered in our Claude Opus 4.6 review. On HLE, they’re close (44.4% vs. 40.0%). However, on GPQA Diamond, Gemini leads both, but Claude edges Grok 4 on most structured output tasks.
The safety-and-transparency comparison is where the two models differ most philosophically. Anthropic’s Constitutional AI approach produces a model with more predictable, more conservative behavior; xAI’s deliberate approach to less-restrictive output produces a model with different content policy boundaries.
At $75 per million output tokens for Claude Opus 4.6 versus $21.25 for standard Grok 4 and $2.50 for Grok 4.3, the cost gap in Grok’s favor is substantial at API scale.
The Honest Verdict: Claude for enterprise writing, planning, and safety-controlled deployments; Grok 4 for cost efficiency at volume and real-time data integration.
Grok 4 vs Gemini 3.1 Pro (Google)
Gemini 3.1 Pro holds the GPQA Diamond record at 94.3%, significantly ahead of Grok 4 Heavy’s 87.5% on graduate-level scientific reasoning. Gemini’s 1-million-token context window is four times Grok 4’s 256K. In addition, Gemini’s Google ecosystem integration (Workspace, YouTube understanding, Search grounding) gives it a structural advantage inside Google’s stack that Grok’s X integration can’t replicate.
On the AA Intelligence Index, Gemini 3.1 Pro scores 57 versus Grok 4.3’s 53, a meaningful but not decisive gap. Our full Gemini 3.1 Pro review covers those benchmarks in depth.
Grok 4.3’s API pricing ($2.50 per output token) is more competitive than Gemini’s $12.00 per output token for developers running high-volume inference. Additionally, for enterprise task performance (GDPval-AA), Grok 4.3’s 321-point ELO improvement surpasses Gemini 3.1 Pro, a significant reversal on that specific benchmark.
The Honest Verdict: Gemini for Google-integrated workflows, long-context processing, and benchmark-leading scientific reasoning; Grok 4 for real-time data, cost efficiency at scale, and enterprise task performance on agentic workloads.
Grok 4 vs DeepSeek V4-Pro

Both are strong models, but they differ fundamentally in openness. DeepSeek V4-Pro is open-source under an MIT license, meaning you can self-host, fine-tune, and deploy it on your own infrastructure, with zero data exposure to third parties.
Grok 4 is a closed, proprietary model; you cannot self-host it or fine-tune it. Our DeepSeek V4 review covers DeepSeek’s full capabilities in detail. DeepSeek leads on coding benchmarks (LiveCodeBench: 93.5%, significantly ahead of Grok 4’s published coding scores) and on API-level cost.
Grok 4 leads on real-time data integration, agentic task performance (particularly post-Grok 4.3 GDPval-AA improvement), and Western enterprise trust requirements. DeepSeek’s China-hosted API remains a documented data residency concern for regulated industries.
The Honest Verdict: DeepSeek for open-weight flexibility, coding, and cost efficiency where data residency is resolved; Grok 4 for real-time X integration, agentic enterprise tasks, and closed-source Western deployment.
Grok 4 vs Llama 4 (Meta)
This comparison is about philosophy as much as it is about performance. Llama 4, Maverick and Scout are open-weight under the Meta Community License.
You can download, modify, and self-host them freely. Grok 4 is proprietary. Llama 4 Scout’s 10-million-token context window dwarfs Grok 4’s 256K-token context window.
Llama 4’s $0.19 per million tokens blended inference cost makes Grok 4.3’s $2.50 output look expensive by comparison, as covered in our Llama 4 explained guide. However, Grok 4’s real-time X integration, agentic tool use, and benchmark performance on specific enterprise reasoning tasks give it an advantage over Llama 4 for users who need managed infrastructure and access to live data.
The Honest Verdict: Llama 4 for open-weight, self-hosted, cost-efficient deployment; Grok 4 for managed real-time data integration and enterprise agentic workflows.
Full Head-to-Head Summary
Criteria | Grok 4 | ChatGPT (GPT-5.4) | Claude Opus 4.6 | Gemini 3.1 Pro | DeepSeek V4-Pro |
HLE (Expert Reasoning) | 44.4% | 39.8% | 40.0% | 44.4% | 37.7% |
GPQA Diamond | 87.5% | 92.8% | N/A | 94.3% | N/A |
Real-Time Data | ✅ X + Web | ⚠️ Web only | ❌ No | ⚠️ Web only | ❌ No |
Context Window | 256K | 128K | 200K | 1M | 1M |
API Output Cost | $21.25 ($2.50 v4.3) | ~$30 | $75 | $12 | $3.48 |
Open-Weight | ❌ No | ❌ No | ❌ No | ❌ No | ✅ Yes |
Self-Hosting | ❌ No | ❌ No | ❌ No | ❌ No | ✅ Yes |
Speed (Tokens/Sec) | 42.5 | Faster | Faster | 123 | Fast |
Agentic Tasks (GDPval) | High (4.3) | N/A | High | Competitive | N/A |
Brand Trust Concerns | ⚠️ Musk/xAI | Low | Low | Low | ⚠️ China-hosted |
Real-World Use Cases: What Grok 4 Does Best
Here’s where Grok 4 actually earns its position; the use cases where it genuinely outperforms alternatives in practice, not just on paper.
Scientific and Academic Research

Grok 4’s HLE score of 44.4% positions it alongside Gemini 3.1 Pro at the top of the frontier for expert-level multi-domain reasoning. For researchers working simultaneously across physics, mathematics, biology, chemistry, and medicine, Grok 4 Heavy’s parallel-agent configuration, in which multiple agents check each other’s reasoning before producing an answer, offers a reliability advantage over single-pass models on high-stakes analytical tasks. Furthermore, xAI’s stated mission to accelerate human scientific discovery is reflected in the training priorities that produced these STEM benchmark results; this is not accidental performance.
Real-Time News and Trend Intelligence
This is where Grok 4 is genuinely irreplaceable. If you need to understand what’s happening on X right now (not three hours ago or yesterday), no other frontier model offers an equivalent tool.
Grok can search posts within a specific time window, find viral content based on an engagement threshold, read the media attached to posts, and synthesize cross-post sentiment in a single query. For journalists, market analysts, communications professionals, and anyone whose work requires understanding real-time public discourse, this capability set has no current equivalent among closed-source competitors.
Agentic Enterprise Workflows
Grok 4.3’s 321-point improvement in performance on the GDPval-AA enterprise task is the benchmark result that matters most for enterprise AI architects evaluating their stack. The model can autonomously invoke web search, X search, code execution, and file/collection search as server-side tools, building multi-step workflows without requiring a human to manage each step transition. Additionally, xAI For Government, launched in August 2025, signals that Grok 4’s agentic capabilities have been evaluated for government-scale deployment, which carries a different quality bar than consumer AI applications.
X (Twitter) Content Creation and Strategy
For creators, brands, and strategists whose primary platform is X, Grok 4 is the natural default AI tool. It understands X’s culture, can analyze specific accounts and trending topics, can draft posts that adhere to X’s formatting conventions natively, and can access engagement data within the platform. Moreover, Grok 4 Code’s native X integration for repository management makes it particularly useful for developers who want to manage their open-source projects and technical content strategy within a unified, AI-assisted workflow.
Developer Tooling via API
The xAI API’s OpenAI-compatible format means you can evaluate Grok 4.3 against your existing GPT integration with minimal code changes. At $1.25 input / $2.50 output per million tokens, Grok 4.3 is now positioned as a cost-competitive alternative for developers running high-volume inference on enterprise reasoning tasks, particularly those that involve multi-step web research, code generation and verification, or document analysis.
For the broader AI tools and productivity landscape that Grok 4 operates within, our AI Unboxed section provides in-depth model reviews, tool comparisons, and developer-focused AI coverage. And, for readers in Africa and emerging markets evaluating AI tools for local deployment (where API cost efficiency is often the decisive factor), Grok 4.3’s dramatically reduced pricing makes it worth serious evaluation. Our AI in Africa coverage tracks how frontier AI tools are being adopted and adapted across African markets.
Limitations and Honest Weaknesses

This section is non-negotiable in any credible AI model review. Grok 4 has real limitations that its official marketing does not emphasize.
The Musk Factor and Why It’s a Legitimate Business Consideration
In July 2025, within a week of Grok 4’s release, it was demonstrated that the model occasionally searches Elon Musk’s views before answering politically sensitive queries, with one response declaring it was “looking” at Musk’s views “to see if they guide the answer.” Additionally, Grok’s political behavior through 2025 was subject to repeated manual adjustments by Musk, including modifications to make it “politically incorrect,” a prompt that led the model to praise Adolf Hitler and refer to itself as “MechaHitler” before being removed, then re-added.
These are documented facts, not speculation. For organizations with reputational exposure, regulatory oversight, or diverse customer bases, the xAI/Musk brand association is a genuine enterprise risk to consider in any honest evaluation.
Verbal Excess
Grok 4 is very verbose; it generated 88 million tokens to run the Intelligence Index evaluations, compared to an average of 36 million for comparable models. In production, this verbosity results in longer-than-necessary responses for many queries, higher token costs per interaction, and outputs that frequently require editing for conciseness. System prompt instructions can mitigate this, but it remains a structural characteristic of the model.
Inference Speed
At 42.5 tokens per second (below the 60.1 t/s median for comparable models) and with a 19.86-second time to first token, Grok 4 is not the right choice for interactive applications that require fast, conversational responses.
Closed Model with No Self-Hosting
Unlike DeepSeek V4-Pro and Llama 4, Grok 4 is proprietary with no open weights available. You cannot self-host it, fine-tune it on proprietary data, or deploy it in an air-gapped environment. Consequently, for organizations with data sovereignty requirements, this is a hard constraint that no API pricing improvement can address.
X Subscription Bundling
Full consumer access to Grok 4 through the standard tiers requires an X Premium+ subscription, which supports a social media platform that not all users want to financially support. The SuperGrok standalone subscription addresses this for users who want AI access without the X platform bundle, but at a higher price than competitors’ equivalent AI-only subscriptions.
Who Should Use Grok 4
Use Grok 4 if you’re already an X Premium+ or SuperGrok subscriber; the jump in capabilities over previous versions is significant enough to justify continued subscription. Use it if your work requires real-time intelligence from X. Breaking news, trend analysis, X-native research, and social sentiment analysis are Grok 4’s genuine differentiators.
Also, use it if you’re a developer who wants to evaluate the xAI API against GPT alternatives; the OpenAI-compatible format makes evaluation easy, and Grok 4.3’s $ 2.50-per-million output-token pricing makes it one of the more cost-competitive frontier-adjacent options currently available. Additionally, use it if you’re doing frontier STEM research and want a model that delivers PhD-level multi-disciplinary reasoning with multi-agent verification available at the Heavy tier.
Who Shouldn’t Use Grok 4

Consider alternatives if your organization has reputational or regulatory concerns about the xAI/Musk brand association. This is a legitimate enterprise risk consideration that won’t disappear. Consider DeepSeek V4-Pro or Llama 4 if you need open-weight models for self-hosting, fine-tuning, or data-sovereign deployment, as covered in our Llama 4 explained guide.
Also, consider Claude Opus 4.6 if your primary need is structured enterprise writing, planning documentation, and safety-controlled output. This is because Claude leads on all of those dimensions.
Consider Gemini 3.1 Pro if you’re inside Google’s ecosystem and need a 1M-token context window, native video understanding, and Search grounding. Our earlier Grok AI review and our Grok vs ChatGPT comparison provide useful additional context for readers comparing Grok’s historical trajectory against competitors.
FAQs
Grok 4 was released on July 9, 2025, built on version 6 of xAI’s foundation model, using 100x more training compute than Grok 2 and 10x more reinforcement learning compute than Grok 3. The primary differences from Grok 3 are: native tool use trained via reinforcement learning (rather than bolted on), a multi-agent Heavy configuration where parallel agents verify each other’s reasoning, significantly improved benchmark performance on HLE and GPQA Diamond, and a 256,000-token context window. Additionally, Grok 4 Code (a coding-specialized variant) and Grok 4.3 (the most current iteration) have extended the original release by improving agentic performance and dramatically reducing API pricing.
On specific benchmarks, HLE expert reasoning (44.4% vs. 39.8%), for example, Grok 4 leads. On speed, consumer ecosystem depth, and plugin library maturity, GPT leads. The most meaningful advantage of Grok 4 is real-time access to X data; no other model can query live posts, trends, and breaking social media conversations. For general-purpose everyday AI use, ChatGPT’s experience is more polished. For research that requires up-to-date social media intelligence, Grok 4 wins.
Yes. Grok 4 is available via the xAI API at docs.x.ai in an OpenAI-compatible format, so you can integrate it into existing OpenAI-based applications by updating the model parameter and endpoint URL. The API supports Grok 4 standard and Grok 4.3, with full access to DeepSearch, code execution, and tool use capabilities. Rate limits and tier-specific features apply based on your API account level.
Conclusion

Grok 4 is the most compelling evidence yet that xAI is a serious AI lab at the frontier, not just a personality-driven chatbot company riding its founder’s fame. The HLE score tying Gemini 3.1 Pro, the 10x reinforcement learning scale-up over Grok 3, the multi-agent Heavy architecture, and the Grok 4.3 iteration’s dramatic cost reduction and agentic performance improvement all reflect genuine technical progress that warrants evaluation on its merits. If you’re currently not paying attention to Grok 4 as a serious alternative to GPT and Claude, that’s a mistake worth correcting.
The limitations I’ve named in this review are equally real, and I won’t soften them for you. The documented political behavior incidents through 2025, the Musk-referencing bias, the excessive verbosity, the closed architecture, and the X subscription bundling are all genuine friction points for enterprise adoption. Additionally, xAI’s founding team instability, with all 10 original co-founders and dozens of researchers having exited the company by the time of Grok 4.3’s launch, is a talent risk that deserves attention from anyone building long-term on xAI’s infrastructure. That said, xAI’s funding depth ($16 billion raised), SpaceX infrastructure backing, and development velocity, from Grok 3 in February 2025 to Grok 4, 4.1, 4.3, and a government product in under a year, suggest that whatever internal disruption occurred, the model development pace has not slowed. Grok 5 is reportedly in preparation. What xAI builds next may be the most important review to read.
The AI model landscape is moving faster than any single review can keep up with. Head to YourTechCompass.com for ongoing model reviews, benchmark updates, and the most current comparisons across every major frontier AI model.


