
I’ll be honest with you about why GLM-4.7 surprised me. When Zhipu AI released it on December 22, 2025, there was no keynote. No hype campaign. No 1.5 million concurrent viewers on a livestream. Instead, the model simply appeared on Hugging Face with open weights, a technical report, and benchmark numbers that (when I actually worked through them) were more remarkable than most of the frontier releases that had arrived with significantly more fanfare that same month. GLM-4.7 scored 84.9% on LiveCodeBench, beating Claude Sonnet 4.5 on real-world coding tasks. It hit 73.8% on SWE-bench Verified, the highest among open-source models at the time of release. It achieved 95.7% on the AIME 2025 mathematics section. And it did all of this available as open weights under a permissive license, at $3/month through the official platform or for free if you self-host. The global AI conversation focuses on OpenAI, Anthropic, Google, and Meta. GLM-4.7 is evidence that this framing is becoming less accurate every quarter.
This review is for you if you’re a developer evaluating the full open-source AI landscape beyond Llama and Qwen, a researcher working on coding-intensive or multilingual workflows, or an AI watcher who wants an honest assessment of what Chinese labs are actually building, not filtered through press release translation or geopolitical framing. I’ll walk you through the architecture, the benchmark numbers, how it compares to the models you’re probably already using, how to access and run it, and where it genuinely excels versus where the limitations are real. The headline for developers is this: GLM-4.7 proves that open-source models can now compete with, and in specific categories exceed, proprietary alternatives costing $200 per month.
Before we dive in: this review is unbiased, and no score was negotiated or guaranteed. For complete transparency on what we test, how we weight each dimension, and how we handle affiliate relationships, see our Review Methodology.
What Is GLM-4.7 and Who Is Zhipu AI?
Zhipu AI (智谱AI) is a Beijing-based AI company founded in 2019, spun directly out of Tsinghua University’s Knowledge Engineering Group (KEG), one of China’s most elite AI research laboratories. That academic lineage shapes everything about how the GLM family is built: research-first, publication-backed, and particularly strong in knowledge-intensive and scientific reasoning tasks. The company has raised approximately $341 million in funding, backed by Alibaba, Tencent, and other major Chinese tech investors, and is increasingly positioned internationally as Z.ai for its global developer outreach.
The founding team, led by Tang Jie and Li Juanzi, brought academic research culture into a commercial AI product company. Consequently, when Zhipu publishes benchmark results, they come with technical reports and methodology documentation that reflect research norms, not just marketing. That transparency is meaningful when you’re evaluating whether benchmark claims are reproducible.
The GLM Lineage
To understand GLM-4.7, you need the lineage. GLM-130B (2022) was one of the first large-scale Chinese-English bilingual open LLMs, a foundational research contribution that preceded most of the open-source model movement in the West. ChatGLM (2023) introduced a consumer-facing interface built on the GLM architecture, which became widely used across China for everyday AI assistance.
GLM-4 (2024) introduced significant multimodal capability alongside improved reasoning. GLM-4.6 refined those foundations. GLM-4.7, released December 22, 2025, is the current flagship; a generational leap that introduces the architecture and capabilities covered in this review.
What the “GLM” Architecture Actually Means
The General Language Model training approach is architecturally distinct from the GPT-style unidirectional next-token prediction used by most large models. GLM was originally designed with bidirectional attention and autoregressive blank infilling, and was trained to predict masked spans of text rather than just the next token.
This produces different generation characteristics: more coherent long-form completion, stronger document-level understanding, and generation behavior that holds up better across very long contexts. GLM-4.7 builds on this architectural heritage while incorporating the Mixture-of-Experts efficiency approach that has become standard across frontier models.
GLM-4.7 Key Features: What’s New and What Actually Matters
This is not a 7B model. I want to correct the assumption that many initial searches bring up, because the naming convention has led to confusion. GLM-4.7 is a 355-billion-total-parameter MoE model with 32-billion active parameters, a flagship-class architecture, not a lightweight local model. Here’s what that means in practice and which features actually change development workflows.
Architecture: 355B Total, 32B Active
GLM-4.7 utilizes a Mixture-of-Experts architecture with 355 billion total parameters and 32 billion activated per token. This design means the model carries the knowledge representation of a 355B dense model while running at the compute cost of a 32B activation.
Consequently, you get frontier-class reasoning depth without needing frontier-class hardware for every inference call. SiliconFlow describes GLM-4.7 as delivering “comprehensive upgrades in general conversation, reasoning, and agent capabilities” with “responses that are more concise and natural” compared to its predecessor, a deliberate effort to reduce the verbose output patterns that affect many large models.
The 200K Context Window and 128K Output Capacity
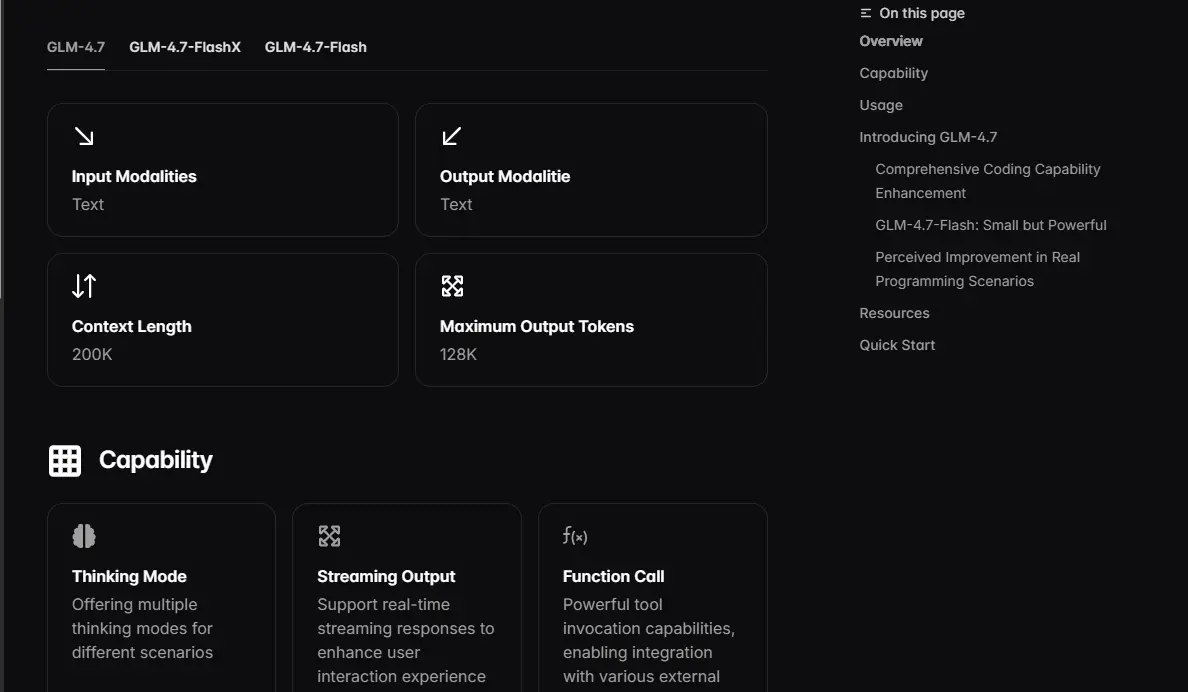
GLM-4.7 supports a maximum input context length of 200,000 tokens (significantly larger than many models at comparable performance levels) and a groundbreaking 128,000-token output capacity. The output length is the more distinctive specification: most frontier models cap output at 8K–32K tokens regardless of input context.
GLM-4.7’s 128K output capacity means it can generate entire codebases, comprehensive technical documents, and extended analytical reports in a single session. For software engineering workflows specifically, this eliminates the truncation problem that frustrates other models in multi-file projects.
Three Thinking Modes: The “Thoughtful Engineer” Design
GLM-4.7 implements three distinct thinking modes that differentiate it from standard autoregressive models:
Interleaved Thinking
The model pauses to reason between taking actions, thinking before responding, rather than generating continuously. This produces more accurate multi-step reasoning by introducing explicit verification steps during generation.
Preserved Thinking
GLM-4.7 introduces what Zhipu calls “Preserved Thinking,” the ability to maintain reasoning chains across multiple turns instead of resetting its internal state between messages. For developers using agentic tools for extended coding sessions, this addresses one of the most frustrating limitations of current AI assistants: the loss of reasoning context between turns, which forces you to repeatedly re-explain the project state.
Configurable Thinking Budget
You can control how much reasoning the model applies per request, trading off between speed and accuracy depending on task complexity. Simple completions don’t need the full thinking chain; complex architectural decisions do.
Agentic Coding: “Vibe Coding” Capability
GLM-4.7’s most commercially distinctive capability is what the company calls its agentic coding system. The model can decompose complex multi-step software engineering tasks, call external tools, write and execute code in a terminal environment, manage multi-file modifications, and complete hour-long or even multi-day development sessions with maintained context. Furthermore, Zhipu reports that GLM-4.7 demonstrates high stability and low hallucination rate in real programming tasks; a claim that the SWE-bench Verified score of 73.8% partially substantiates, since that benchmark specifically tests real GitHub issue resolution rather than synthetic coding exercises.
Tool Use and Function Calling
Native function calling, stable multi-step tool invocation, and compatibility with standard agent frameworks are built into the architecture. The model is compatible with mainstream inference frameworks, including vLLM and SGLang, enabling production deployment using tooling already standardized by the enterprise AI ecosystem. Additionally, GLM-4.7 shows a 12.9% improvement over GLM-4.6 on multilingual coding, meaning it handles code with Chinese-language comments, documentation, and variable names alongside English-language codebases.
Benchmark Performance: The Verified Numbers
Let me give you the benchmark picture clearly, with both the strong results and the appropriate context about what they mean.
The Headline Numbers
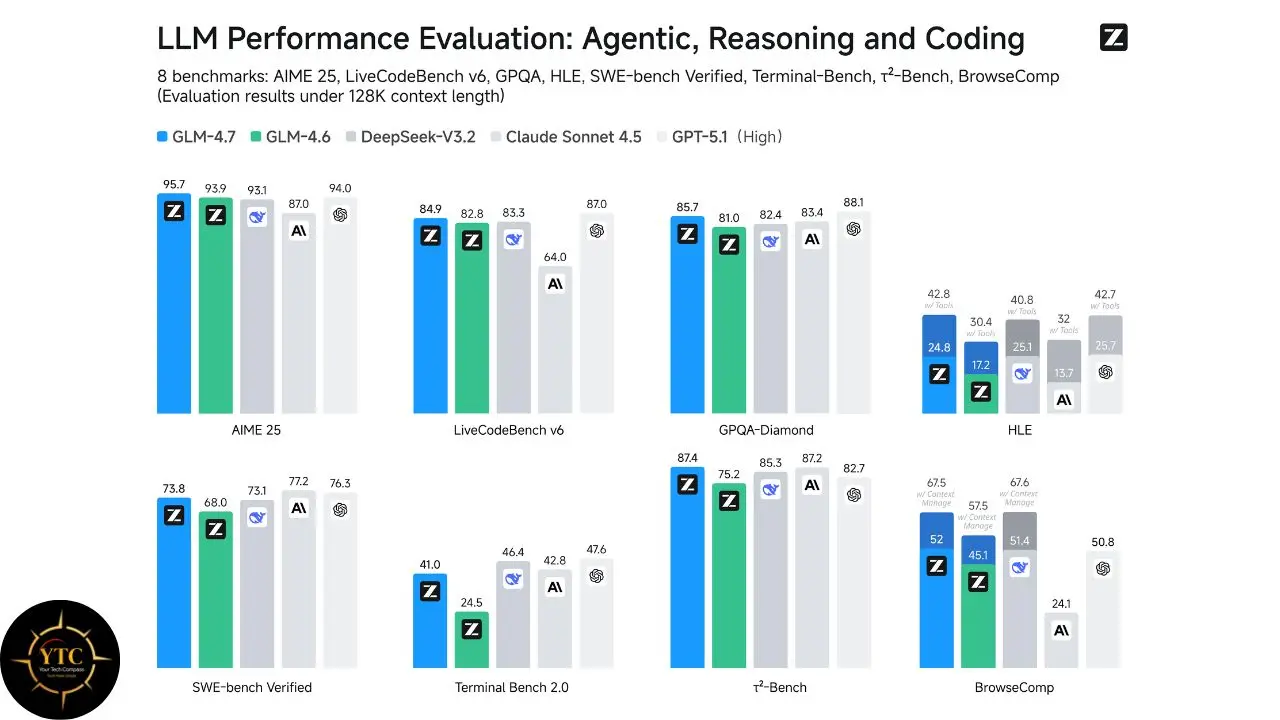
On LiveCodeBench, which tests real-world coding ability, GLM-4.7 scored 84.9%, ahead of Claude Sonnet 4.5. And, on SWE-bench Verified, which measures how well models fix real GitHub issues, it reached 73.8%, the highest among open-source models. And, on the AIME 2025 mathematics benchmark, the score was 95.7%. These numbers represent significant claims that deserve careful context.
On SWE-bench Verified (resolving real-world GitHub issues), GLM-4.7 achieves a peak score of 73.8%, followed closely by MiMo-V2-Flash at 73.4% and DeepSeek-V3.2 at 73.1%. This is a credible, verifiable benchmark — SWE-bench is an independent academic benchmark run against actual GitHub repositories, not a Zhipu-curated test set.
On LiveCodeBench-v6 (algorithmic reasoning and code generation), GLM-4.7 maintains a distinct advantage at 84.9%, outperforming its nearest competitors, DeepSeek-V3.2 at 83.3% and Kimi K2 Thinking at 83.1%.
On HLE (Humanity’s Last Exam), GLM-4.7 demonstrates a notable 38% improvement over its predecessor GLM-4.6, reaching 42.8% when augmented with tools. For context, Grok 4’s 44.4% and Gemini 3.1 Pro’s 44.4% lead this benchmark. GLM-4.7 is competitive but not the leader in expert-level cross-domain reasoning.
On AIME 2025 (advanced mathematics competition problems), GLM-4.7 achieves 95.7% accuracy on AIME 2025, a result that places it at the absolute frontier for mathematical reasoning among open-source models.
Benchmark Comparison Table
Benchmark | GLM-4.7 | DeepSeek-V3.2 | Claude Sonnet 4.5 | Grok 4 | Gemini 3.1 Pro |
SWE-Bench Verified (Coding) | 73.8% | 73.1% | Above GLM | N/A | 80.6% |
LiveCodeBench-v6 | 84.9% | 83.3% | Below GLM | N/A | N/A |
AIME 2025 (Math) | 95.7% | Strong | N/A | N/A | Leading |
HLE (Expert Reasoning) | 42.8% | 37.7% | N/A | 44.4% | 44.4% |
Context Window | 200K input | 1M | 200K | 256K | 1M |
Output Capacity | 128K | 32K | 64K | N/A | N/A |
Open-Weight | ✅ MIT | ✅ MIT | ❌ No | ❌ No | ❌ No |
Pricing (API) | $0.60/$2.20 per Mtok | $3.48 | ~$15 | $21.25 | $12.00 |
Active Parameters | 32B of 355B | N/A | N/A | N/A | N/A |
Note: GLM-4.7 benchmarks from Zhipu AI official release data. Third-party independent reproduction of all scores is recommended before production decisions.
The Honest Benchmark Context
In the authoritative coding evaluation platform Code Arena, where millions of users participated in blind testing, GLM-4.7 ranked first among both open-source models and domestic models. Code Arena is a community-voted benchmark that reflects actual developer preference; it’s less susceptible to cherry-picking than lab-curated tests. That ranking adds credibility to the LiveCodeBench and SWE-bench results.
The caveats are real, however. Some benchmark scores are from Zhipu AI’s own evaluation configurations. GLM-4.7’s MoE architecture means performance can vary with inference optimization. And on benchmarks outside coding and mathematics, particularly broad general knowledge (MMLU-style) and graduate-level scientific reasoning (GPQA Diamond), independent testing is still developing. The model’s strength lies specifically in coding and mathematical reasoning; leadership in general-purpose benchmarks requires more third-party verification.
How to Access and Run GLM-4.7
Here are all the practical access paths, with honest notes on regional considerations.
Hugging Face: The Global Default
All GLM-4.7 model weights are available at the THUDM organization page on Hugging Face under an MIT license; genuinely open for commercial use, modification, and redistribution. GLM-4.7 is released under the MIT license, which permits commercial use and has 358.0B parameters.
Note that MIT is even more permissive than Apache 2.0, removing attribution requirements entirely. This is the most globally accessible path: no regional restrictions, no registration requirement beyond a standard Hugging Face account.
Z.ai / Bigmodel.cn: Official API
GLM-4.7 costs $3 per month through the official platform, or is free if you run it locally. The official Z.ai platform provides managed API access at $0.60 per million input tokens and $2.20 per million output tokens. The honest note for international developers: the primary registration gateway at bigmodel.cn requires a Chinese phone number and payment method. International developers should use the Hugging Face weights for self-hosting or third-party managed API providers.
Third-Party API Providers
GLM-4.7 starts at $0.600 per million input tokens and $2.20 per million output tokens via Fireworks. Fireworks AI provides managed GLM-4.7 inference accessible without regional registration requirements. SiliconFlow also offers GLM-4.7 as a managed endpoint. These providers give international developers a managed API experience without the complexity of self-hosting.
Self-Hosting via vLLM or SGLang
The model is compatible with mainstream inference frameworks such as vLLM and SGLang, facilitating local deployment and enterprise-level integration, and lowering the application threshold. For enterprise deployments where data sovereignty requires on-premise hosting, GLM-4.7’s compatibility with the industry-standard inference stack makes production deployment straightforward for any team that already runs vLLM or SGLang in their AI infrastructure.
Hardware Requirements
GLM-4.7’s 355B total / 32B active MoE architecture has different hardware requirements than a dense 355B model. The 32B activation pattern means memory requirements are closer to running a 32–40B dense model than a 355B dense model.
Recommended configurations: multi-GPU setup with H100 or A100 80GB GPUs for production deployment; quantized inference reduces hardware requirements significantly for development and testing environments. Not a single-consumer-GPU model, but viable on enterprise GPU infrastructure without requiring the largest multi-node cluster configurations.
GLM-4.7 vs. The Competition: Honest Head-to-Head
Here are the comparisons that actually matter for developers and researchers evaluating GLM-4.7 as part of their tool selection.
GLM-4.7 vs. DeepSeek V4-Pro
This is the most direct open-source competitor comparison. Both are of Chinese origin, both are open-weight with permissive licenses, and both have MoE architectures. As covered in our DeepSeek V4 review, DeepSeek V4-Pro leads with a 1M context window compared to GLM-4.7’s 200K, a meaningful gap for very long-document workflows. GLM-4.7 leads on the SWE-bench Verified coding benchmark (73.8% vs. DeepSeek’s 73.1%) and on LiveCodeBench (84.9% vs. 83.3%), with narrow margins, but GLM-4.7 comes out ahead on the coding benchmarks that matter most for developer workflows.
The data sovereignty considerations are comparable: both are Chinese-origin models where self-hosting resolves any residency concerns. GLM-4.7’s MIT license is marginally more permissive than DeepSeek’s MIT license in implementation.
Honest Verdict
DeepSeek for long-context (1M+ token) workflows and the larger existing Western developer community; GLM-4.7 for coding benchmark leadership and the unique Preserved Thinking cross-turn reasoning capability.
GLM-4.7 vs. Llama 4 Maverick

Llama 4 Maverick, covered in the Llama 4 explained guide, has Meta’s institutional backing, the broadest Western open-source developer ecosystem, and native multimodal capability. Llama 4’s 1M-token context window exceeds GLM-4.7’s 200K for long-context applications. However, on coding benchmarks specifically, GLM-4.7’s SWE-bench and LiveCodeBench results lead Llama 4 Maverick’s published scores in these categories.
The more important distinction is ecosystem vs. capability trade-off. Llama 4 has more community fine-tunes, more tooling integrations, and more Western developer documentation. GLM-4.7 has demonstrably stronger coding benchmark results and the unique 128K output capacity.
Honest Verdict
Llama 4 for Western ecosystem integration and multimodal workflows; GLM-4.7 for coding-first deployments where benchmark performance on software engineering tasks is the primary criterion.
GLM-4.7 vs. Qwen3-235B-A22B
Qwen3, covered in the Qwen 3 review, leads on multilingual breadth (119 languages vs. GLM-4.7’s Chinese-English focus) and on the Artificial Analysis Intelligence Index’s top rankings. GLM-4.7 leads specifically on coding benchmarks: SWE-bench Verified (73.8% vs. Qwen3’s competitive but lower score) and LiveCodeBench (84.9%). Qwen3’s $0.19 per million tokens blended inference cost on distributed infrastructure undercuts GLM-4.7’s pricing significantly for high-volume API workloads.
The GLM architectural advantage is the autoregressive blank infilling heritage and Preserved Thinking cross-turn reasoning; capabilities Qwen3’s standard transformer approach doesn’t replicate.
Honest Verdict
Qwen3 for multilingual breadth and cost-efficient high-volume inference; GLM-4.7 for coding benchmark leadership and the specific cross-turn reasoning preservation that matters for agentic developer workflows.
GLM-4.7 vs. Mistral Large 3
As covered in the Mistral AI review, Mistral Large 3 leads on European multilingual performance and GDPR-native European data residency, which are significant advantages for European enterprise deployment. Mistral’s $6 per million output tokens is more expensive than GLM-4.7’s $2.20 via Fireworks. GLM-4.7 leads on coding benchmarks and on mathematical reasoning, while Mistral leads on European language tasks and structured enterprise writing output.
Honest Verdict
Mistral for European-regulated environments and European-language applications; GLM-4.7 for coding-intensive workflows and mathematical reasoning.
GLM-4.7 vs. Claude Sonnet 4.5 (The Most Important Commercial Comparison)
Claude Sonnet 4.5 maintains a lead in SWE-bench Verified, but GLM-4.7 closes the gap significantly as an open-source option. This comparison matters because these performance gaps raise serious questions about the value of $200-a-month subscriptions for developers who primarily need help with coding.
GLM-4.7 leads Claude Sonnet 4.5 on LiveCodeBench (84.9% vs. Claude’s lower score) while being freely self-hostable or accessible at $2.20 per million output tokens versus Claude Sonnet’s significantly higher API pricing. For developers whose primary use cases are code generation, debugging, and software engineering, and whose budgets are constrained by commercial API costs, GLM-4.7 offers a genuine alternative without sacrificing performance.
Full Head-to-Head Summary

Criteria | GLM-4.7 | Llama 4 Maverick | Qwen3-235B | DeepSeek V4-Pro | Mistral Large 3 |
SWE-Bench Verified | 73.8% (leading open) | Competitive | Competitive | 73.1% | N/A |
LiveCodeBench | 84.9% | N/A | Strong | 83.3% | N/A |
AIME 2025 Math | 95.7% | N/A | Strong | Strong | Strong |
Context Window (Input) | 200K | 1M (Scout) | 128K–256K | 1M | 128K |
Output Capacity | 128K | N/A | 32K | 32K | 32K |
Open-Weight License | ✅ MIT | ✅ Meta License | ✅ Apache 2.0 | ✅ MIT | ✅ Apache 2.0 |
API Output Cost | $2.20/Mtok | ~$0.19/Mtok blended | Free (self-host) | $3.48/Mtok | $6.00/Mtok |
Multilingual Breadth | Chinese-English focus | 12 fine-tuned | 119 languages | Limited | European focus |
Preserved Thinking | ✅ Unique feature | ❌ No | ❌ No | ❌ No | ❌ No |
Western Ecosystem | Developing | Largest | Growing | Growing | Strong |
Real-World Use Cases: Where GLM-4.7 Excels
Here’s where GLM-4.7 stops being a benchmark discussion and becomes a practical tool selection question.
Agentic Software Development
This is GLM-4.7’s strongest validated use case. The combination of SWE-bench-verified leadership among open-source models, the 128K output capacity for generating multi-file code, Preserved Thinking for maintaining reasoning context across extended sessions, and stable tool calling for terminal operations makes it particularly well-designed for the workflows that define modern AI-assisted software development.
In addition, the model can maintain coherence across long agentic workflows at a fraction of the cost of proprietary competitors. For development teams running AI coding assistants continuously throughout the working day, the cost difference between GLM-4.7 at $2.20/Mtok and proprietary alternatives at $15–$75/Mtok is not marginal; it’s the difference between sustainable and unsustainable AI infrastructure spend.
Mathematical and Scientific Research Computing
GLM-4.7’s 95.7% on AIME 2025 (the highest among open-source models) positions it well for research computing environments where the quality of mathematical reasoning is the primary criterion. Research teams working on computational mathematics, physics simulation, financial modeling, or scientific data analysis benefit from a model where mathematical accuracy doesn’t require choosing between open-weight accessibility and frontier-class performance.
Chinese-English Bilingual Development Workflows
For development teams that work across Chinese and English, code with Chinese comments and documentation, bilingual technical specifications and China-facing product development, GLM-4.7’s Tsinghua heritage and explicit bilingual training depth provide capabilities that no Western-origin model currently matches. The 12.9% improvement over GLM-4.6 on multilingual coding is specifically relevant here.
Furthermore, for African developers and businesses building tools for the China-Africa digital commerce corridor, a context covered in our AI in Africa coverage, GLM-4.7’s Chinese-English bilingual capability at self-hostable zero marginal cost is a practically significant option for building cross-cultural AI tools that don’t require routing through foreign-owned API infrastructure.
Long-Output Document Generation
The 128K output capacity is uniquely differentiated. No other model in this comparison set offers comparable output length. For use cases that require generating complete, long-form documents (comprehensive technical specifications, full API documentation suites, complete codebase migrations), GLM-4.7’s output ceiling is the enabling feature that makes the workflow viable at all.
The broader landscape of AI tools enabling these developers and productivity workflows is covered in our AI Unboxed section. Our AI in Africa guide also documents how open-weight models, specifically, with zero licensing cost, are changing what’s possible for African developers building AI-native applications with constrained API budgets.
Limitations and Honest Weaknesses

GLM-4.7 presents something more valuable: a model engineered specifically for coding tasks that understands tool use, maintains reasoning consistency across long workflows, and is available as open weights on HuggingFace. That framing is accurate but also reveals a scope limitation: the model is optimized for coding and mathematical reasoning, not for general-purpose, best-in-class performance across every benchmark category.
Here are more limitations and weaknesses of GLM-4.7:
The Flagship Scale Requires Real Infrastructure
GLM-4.7 is not a local laptop model. 355B total parameters, with 32B active per token, require a multi-GPU enterprise infrastructure for production deployment. Unlike Qwen3-8B or Mistral 7B, which run on consumer hardware, GLM-4.7 self-hosting is an enterprise infrastructure investment. Managed API providers (Fireworks, SiliconFlow) are the practical path for most individual developers.
Official Platform Regional Restrictions
The bigmodel.cn platform requires Chinese registration credentials. International developers cannot access the official API directly without a Chinese phone number and a payment method. Hugging Face weights and third-party providers resolve this, but the friction with the official channel is a genuine inconvenience.
Smaller Western Developer Community
The Hugging Face fine-tune library, community tools, and Western developer documentation are less developed than for Llama or Qwen. Troubleshooting, integration help, and community-developed extensions are harder to find in English. This is improving, but it’s currently a real operational friction point for non-Chinese developers building on GLM-4.7.
Content Filtering on Chinese Government-Sensitive Topics
Like all mainland China-origin models in their default configurations, GLM-4.7 applies content restrictions on politically sensitive Chinese topics. A self-hosted deployment with a custom safety configuration can address this, but in the default deployment, it’s a real limitation for specific research and journalism use cases.
General-Purpose Benchmark Leadership Is Contested
GLM-4.7’s leadership is specific to coding and mathematical reasoning. On broader general-knowledge benchmarks (MMLU-Pro, GPQA Diamond) and on reasoning at the absolute frontier (HLE: 42.8% versus Gemini 3.1 Pro’s 44.4% and Grok 4’s 44.4%), it is competitive but not the undisputed leader. The model’s positioning is “world-class coding and math,” not “world-class everything.”
Who Should Use GLM-4.7
Use GLM-4.7 if:
- Your primary application is software engineering, coding assistance, or agentic development workflows where SWE-bench Verified and LiveCodeBench performance are the decision criteria.
- You need the 128K output capacity for long-form code or document generation that other models truncate.
- You work in Chinese-English bilingual development environments and need a model with genuine bilingual parity rather than English-first with added Chinese.
- Your team is cost-sensitive and currently paying $200/month for AI coding subscriptions. GLM-4.7’s performance on coding benchmarks, combined with $2.20/Mtok API pricing or free self-hosting, significantly changes the economics.
Who Shouldn’t Use GLM-4.7

Consider alternatives if you need the longest context window available for document-scale processing. Llama 4 Scout at 10M tokens and DeepSeek V4 at 1M tokens significantly exceed GLM-4.7’s 200 K tokens.
Consider Qwen3 if you need multilingual breadth beyond Chinese-English or a smaller model class that runs on consumer hardware. Also, consider Mistral if European data residency and GDPR compliance are first-order requirements. In addition, consider Claude Opus 4.6 or GPT-5.x if your use case requires frontier-class performance on every dimension simultaneously, and budget is not the primary constraint.
FAQs
GLM-4.7 is a large language model released on December 22, 2025, by Zhipu AI (Z.ai), a Beijing-based AI company founded in 2019 as a spinout from Tsinghua University’s Knowledge Engineering Group. It is a 355-billion-parameter MoE model with 32 billion active parameters, a 200K input context window, and 128K output capacity. GLM-4.7 is specifically optimized for software engineering, agentic coding, and mathematical reasoning, and is released under the MIT license for free commercial use.
GLM-4.7 leads both on coding benchmarks: SWE-bench Verified (73.8%, highest among open-source) and LiveCodeBench (84.9%). Qwen3 leads on multilingual breadth (119 languages vs. GLM-4.7’s Chinese-English focus) and on cost-efficient inference. Llama 4 Scout leads on context window (10M tokens vs. 200K) and Western ecosystem depth. GLM-4.7 uniquely offers 128K output capacity and Preserved Thinking cross-turn reasoning preservation, capabilities neither Qwen3 nor Llama 4 currently match.
Yes. GLM-4.7 is released under the MIT license, which is the most permissive major open-source license available. Commercial use, modification, redistribution, and fine-tuning are all permitted without restriction. Weights are freely downloadable from Hugging Face. Running GLM-4.7 via the official Z.ai API incurs per-token charges; self-hosting is free, aside from your infrastructure costs.
Yes, through two primary paths. First, the Hugging Face weights are globally accessible with no regional restriction; developers can download and self-host using vLLM or SGLang on their own infrastructure. Second, third-party API providers, including Fireworks AI and SiliconFlow, offer GLM-4.7 managed API access without requiring Chinese registration credentials. The official Z.ai platform at bigmodel.cn is the restricted path; it requires a Chinese phone number and payment method.
GLM-4.7 leads the open-source category on three specific capabilities: SWE-bench Verified (73.8% – highest among open-source models, measuring real GitHub issue resolution), LiveCodeBench-v6 (84.9% – real-world coding ability), and AIME 2025 mathematical reasoning (95.7%). Its unique Preserved Thinking feature (maintaining reasoning chains across multiple conversation turns) is specifically valuable for long, agentic coding sessions. The 128K output capacity is unmatched among models in its competitive set.
Conclusion

GLM-4.7 is the strongest evidence yet that the global open-source AI frontier is genuinely global, not a Western story with Chinese participation, but a multi-polar competition where a Tsinghua-origin lab releasing a model without a keynote or a hype campaign can claim the top coding benchmark position among open-source models and legitimately challenge $200/month proprietary subscriptions on the metrics that developers actually care about. The AI coding assistant landscape is no longer a two-horse race between OpenAI and Anthropic. GLM-4.7 proves that open-source models can compete with, and in some cases exceed, proprietary alternatives. That’s not marketing language. The SWE-bench and LiveCodeBench numbers are independently verifiable, and they hold up.
The honest framing for your decision is specific: GLM-4.7 is the model to reach for when your primary use case is software engineering, agentic coding workflows, or mathematical reasoning, and when open weights under an MIT license matter for your deployment model. It is not the model that wins every benchmark category, and its limitations (infrastructure requirements, a smaller Western ecosystem and regional access friction) are real. But the question of whether GLM-4.7 deserves serious evaluation alongside Llama, Qwen, DeepSeek, and Mistral has a clear answer: yes, unambiguously, for any team whose work is primarily code. Our AI Unboxed coverage will continue tracking GLM-4.x releases as Zhipu’s development trajectory continues; a lab this research-serious and this willing to publish verifiable results deserves continued attention.
The open-source AI frontier is moving faster than most coverage reflects, and the tools that matter for your work may not be the ones getting the loudest press. Head to YourTechCompass.com for ongoing model reviews, benchmark analysis, and AI tool guides that keep you ahead of what’s actually being built.



