Generative AI is the most significant shift in how software works since the invention of the internet. That’s not a headline; it’s a description of what’s actually happening. In the span of two years, a technology that existed primarily in research papers has become the engine behind search engines, writing tools, customer service systems, creative platforms, and coding assistants used by hundreds of millions of people every day. And yet, for all the coverage it generates, most people still have a fuzzy sense of what generative AI actually is, how it produces what it produces, and why it behaves the way it does.
I want to fix that in this article, not with hype or oversimplification, but with a clear, honest explanation that gives you a working understanding of the technology. You’ll understand what generative AI is, how it differs from older AI systems, the architectures that power it, how it’s being used across real industries right now, and the genuine risks you should understand before relying on it. By the end, you’ll have the mental model that most people who use these tools daily lack.
What Generative AI Actually Is
Generative AI is a category of artificial intelligence systems that can create new content, text, images, audio, video, code, or any combination of these, rather than simply analyzing or classifying existing data. The word “generative” is doing real work there. The distinction between analyzing and generating is the entire story.
Older AI systems were discriminative; they were trained to distinguish between things. Is this email spam or not? Is this image a cat or a dog? Does this transaction look fraudulent?
These are classification problems, and traditional machine learning handles them well. What those systems can’t do is produce something new. Ask a spam classifier to write an email, and it has no response. It can only evaluate; it cannot create.
Generative AI systems do something fundamentally different. They learn the underlying patterns in training data: the structure of language, the relationships between visual elements, the architecture of code, and then use those patterns to generate original outputs that resemble what they were trained on. Feed a generative AI system enough human-written text, and it learns the patterns of how humans write well enough to write new text. Feed it enough images, and it learns the visual patterns well enough to generate new ones.
This makes generative AI more flexible than any previous category of AI. A single large generative model can write an essay, translate a document, answer a technical question, write a function in Python, and explain a medical concept, all from the same underlying architecture, because all of these tasks involve predicting patterns in language. That versatility is why generative AI is transforming industries simultaneously rather than one at a time.
How Generative AI Actually Works
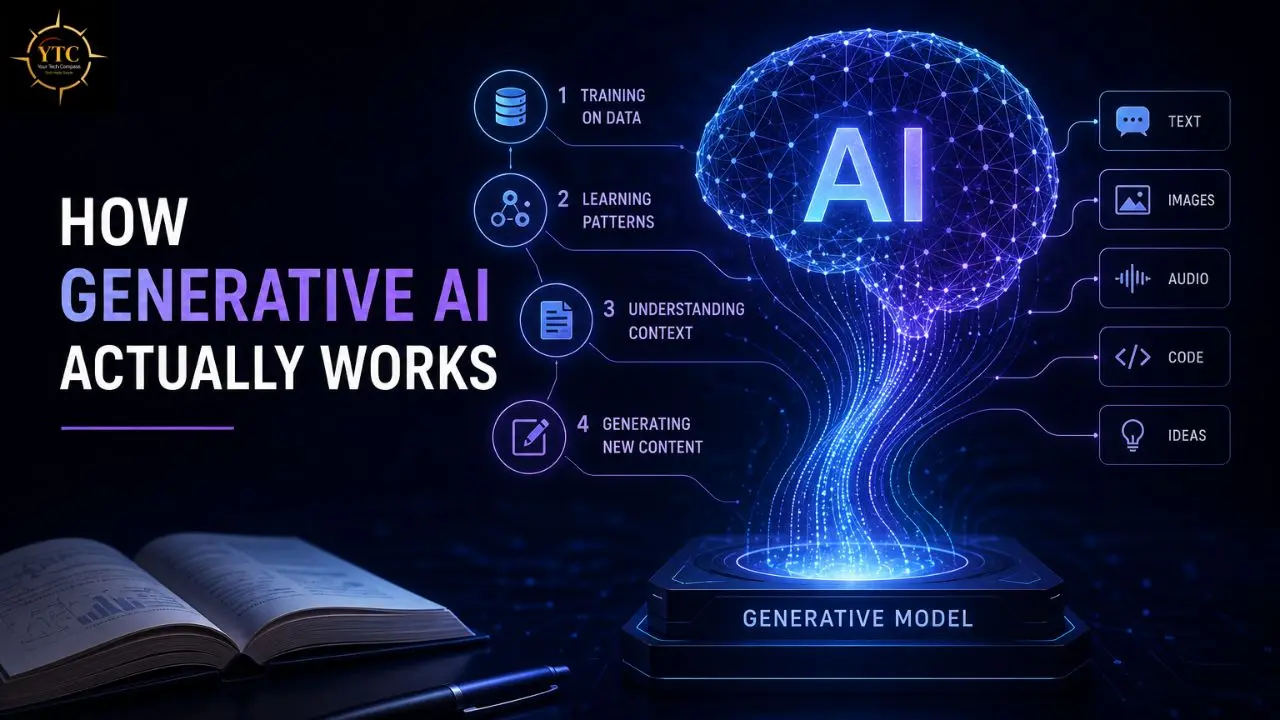
This is the section that most explainers skip or reduce to a vague paragraph about “learning patterns.” I’m going to be more specific, because understanding the mechanism helps you understand both the capabilities and the limitations, including why the technology sometimes gets things wrong.
Tokens and Embeddings: The Building Blocks
Before a language model processes any text, it converts it into tokens. A token is not always a word; it’s a chunk of text that the model treats as a unit.
The word “unhappiness” might be a single token, or it might be split into “un,” “happiness.” “ChatGPT” might be one token. A space before a word might be part of the token. This tokenization step converts human language into a numerical form that the model can process mathematically.
Each token is then converted into an embedding, a high-dimensional numerical representation that encodes not just the token itself but its meaning in context. Words with similar meanings end up with similar numerical representations. This is what allows models to understand that “car,” “automobile,” and “vehicle” are related concepts without being explicitly told. The model learns these relationships from patterns in training data.
Transformers: The Architecture Behind Language Models
In the universe of generative models, two types stand out due to their effectiveness and widespread use: diffusion models and transformers. These architectures have redefined the landscape of machine learning, and understanding them provides valuable insight into how models generate new data.
The transformer architecture, introduced by Google researchers in a 2017 paper titled “Attention Is All You Need,” is the foundation of every major language model in use today, including GPT-4o, Claude Opus, Gemini, and Llama. Transformers use an attention mechanism that analyzes training data by breaking input into tokens that represent parts of the data. For example, if the input is a sentence, the tokens might be individual words.
The “attention” mechanism is what makes transformers so powerful. Instead of processing words sequentially (one by one, left to right), the transformer processes all tokens simultaneously and learns which tokens are most relevant to each other for understanding meaning.
When processing the word “it” in a sentence, the attention mechanism figures out which earlier word “it” refers to. This parallel processing is both what makes transformers so capable and why they require enormous computational resources to train.
When a language model generates text, it’s not retrieving a stored answer from memory. It predicts the most likely next token based on everything that came before: your prompt, the conversation history, and the context window.
It does this one token at a time, feeding each generated token back in as context for predicting the next one. The output that feels like fluent, coherent writing is the result of millions of these sequential probability predictions happening in fractions of a second.
This mechanism explains something important about how language models fail: they don’t “know” facts in the way humans do. They’ve learned patterns about which words tend to appear together in which contexts.
When a model states an incorrect fact with confidence, it’s because the incorrect answer has a high probability given the patterns in training data, not because the model has looked something up and found a wrong answer. The model is always predicting, never retrieving.
Diffusion Models: How AI Generates Images

Diffusion models work by adding noise to the available training data and then learning how to reverse the process. The reverse operation may then be applied to new random data in order to produce new outputs.
In Concrete Terms
During training, a diffusion model takes real images and gradually corrupts them by adding random noise, step by step, until the image is pure static. The model learns, at each step, how to predict what the image looked like before the noise was added. After training, the model can run this process in reverse, starting from pure random noise and progressively removing noise to produce a coherent image that matches a text prompt.
Diffusion models take longer to train than VAEs or GANs, but ultimately offer finer-grained control over the output, particularly for high-quality image generation. DALL-E, OpenAI’s image-generation tool, is driven by a diffusion model. So are Midjourney, Stable Diffusion, and most of the image generation tools you’d recognize by name.
GANs: The Earlier Approach to Image Generation
Before diffusion models became dominant, Generative Adversarial Networks (GANs) were the primary architecture for image generation. GANs are one of the architectures generative AI relies on to produce outputs that feel surprisingly human.
A GAN consists of two neural networks training against each other: a generator that creates fake images, and a discriminator that tries to tell fake images from real ones. The generator gets better at fooling the discriminator; the discriminator gets better at detecting fakes. This adversarial process produces increasingly realistic outputs.
GANs are still used in specific applications, particularly video generation and image-to-image translation, but diffusion models have largely superseded them for pure image generation because diffusion models produce more varied, higher-quality outputs and are more stable to train.
Training at Scale: What Makes Models Capable
The performance of any generative AI system correlates directly with three variables: the size of the training dataset, the number of model parameters (the learnable values that encode its knowledge), and the computational resources used during training.
Modern frontier language models are trained on datasets measured in trillions of tokens; essentially, a significant fraction of everything humans have written and published online, plus books, code repositories, scientific papers, and more. They contain hundreds of billions to over a trillion parameters.
Training a single frontier model costs tens of millions to over a hundred million dollars in compute. This is why there are relatively few frontier model developers; the barrier to entry is primarily financial and infrastructural.
The trained model is then typically refined through a process called Reinforcement Learning from Human Feedback (RLHF), in which human raters evaluate model outputs and their preferences are used to fine-tune the model to be more helpful, more accurate, and less prone to harmful outputs. This is the step that takes a capable but raw language model and turns it into a useful assistant.
The Major Categories of Generative AI
Understanding the landscape of what generative AI produces helps clarify which tools are relevant to which use cases.
Text Generation and Large Language Models

Text generation is the most familiar application. Large language models (LLMs) like GPT-4o, Claude Opus, and Gemini can write articles, emails, and reports; summarize long documents; translate between languages; explain complex topics; answer questions; and generate or debug code. The same underlying model handles all of these tasks because they all reduce to a single operation: predicting the next word given context.
Conversational AI tools like Character AI apply the same language model technology to persona-driven conversation, allowing users to interact with AI characters that maintain consistent personalities across exchanges.
Image Generation
Text-to-image models, powered by diffusion models, generate original images from written descriptions. You type “a photorealistic portrait of an elderly fisherman in morning light, digital photography,” and the model produces an image matching that description.
Tools like Midjourney, DALL-E 3, and Stable Diffusion XL fall into this category. The quality of modern image generation is high enough that AI-generated images are regularly mistaken for photographs by untrained observers.
Video Generation
Video generation was where the technology stood in 2022: impressive and obviously artificial. By 2026, tools like OpenAI’s Sora, Google’s Veo 3, and Runway’s Gen-4 are producing short videos from text prompts with temporal coherence and cinematic quality that, in favorable conditions, is genuinely difficult to distinguish from filmed footage.
Audio and Voice Generation
Voice synthesis tools can clone a voice from a short audio sample and generate unlimited speech in that voice. Music generation tools compose original tracks in specified genres and styles. Voice AI platforms like Poly AI apply generative audio to conversational business applications, replacing scripted IVR systems with AI voice agents that can handle natural, unscripted customer interactions.
Code Generation
Code generation models (specialized or general language models fine-tuned on code) can write, explain, debug, and refactor code across dozens of programming languages. Tools like GitHub Copilot, Blackbox AI, and Cursor have made code generation a standard part of developer workflows, with studies finding that developers using AI coding assistants complete tasks 55% faster on average.
Generative AI vs. Traditional AI: A Real Comparison

Feature | Traditional AI | Generative AI |
Primary Function | Classify, detect, predict | Create new content |
Output | Label, score, category, or number | Text, image, audio, video, code |
Training Data Use | Learn decision boundaries | Learn underlying data distributions |
Adaptability | Task-specific | Generalizes across many tasks |
Representative Tools | Spam filter, fraud detector, face ID | ChatGPT, Midjourney, GitHub Copilot |
Failure Mode | Incorrect classification | Confident hallucination |
User Interaction | Usually invisible/backend | Direct, conversational |
The practical difference in daily life: traditional AI is running quietly in the background; the system that flags your credit card transaction as suspicious, the algorithm ranking your search results, the model detecting objects in a self-driving car’s camera feed. Generative AI is what you interact with directly: the writing assistant, the image generator, the AI search tool, the coding companion.
Where Generative AI Is Being Used Right Now
The applications of generative AI in 2026 extend across nearly every industry. Here’s where the impact is most documented and verified.
Search and Research
AI-powered search tools like Perplexity AI have changed how people research by combining live web retrieval with generative synthesis, returning a sourced, natural-language answer rather than a list of links to read. Google’s AI Overviews, Bing Copilot, and similar features integrate generative AI directly into the search interface.
Software Development
Code generation has become one of the most widely adopted applications of generative AI among professional users. Developers use LLMs to generate boilerplate code, explain unfamiliar codebases, catch bugs, write unit tests, and convert code between languages. The productivity gains in this domain are among the most measurable of any generative AI application.
Healthcare and Drug Discovery
In drug discovery, generative AI is being used to design novel molecular structures with specific properties, dramatically accelerating the early stages of pharmaceutical research. AI models can predict protein structures (AlphaFold 3), suggest candidate drug compounds, and generate synthetic medical imaging data for training diagnostic models. Radiologists are using generative AI to draft preliminary reports from scan data; pathologists are using it to analyze tissue slides at scale.
Creative Industries
Generative AI has restructured creative workflows for writers, designers, marketers, and filmmakers. Writers use it for research, first-draft generation, and editing. Designers use it for rapid concept generation and visual prototyping.
In addition, marketing teams use it to produce content variations at scale. Film studios use generative AI for pre-visualization, VFX generation, and voice dubbing for international markets.
Customer Service and Enterprise Automation
Businesses have deployed generative AI to handle customer service interactions, process and summarize documents, draft communications, and automate workflows that previously required human labor. Enterprise adoption has been rapid: Gartner projects that more than 80% of enterprises will have used generative AI APIs or deployed generative AI-enabled applications by 2026.
Education
Generative AI is functioning as an on-demand tutor, available at any hour and infinitely patient with follow-up questions. Students use it for explanations of difficult concepts, worked examples, essay feedback, and practice problems. The educational use case is simultaneously one of the most promising (democratizing access to tutoring) and one of the most contested (concerns about academic integrity and over-reliance).
The Real Risks of Generative AI
The original article mentioned hallucination, bias, and copyright; three sentences each. These deserve substantially more honest treatment, because understanding the risks is what makes you a sophisticated user rather than a credulous one.
Hallucination: Confident Wrongness
Hallucination is the term for when a generative AI system produces content that is factually incorrect, presented with the same fluency and confidence as correct information. This isn’t a bug in the traditional sense; it’s an inherent property of how language models work. The model is always predicting the most probable next token based on patterns. Sometimes the most probable next token is wrong.
Hallucination is most dangerous in domains where accuracy is critical, such as medical information, legal citations, financial data, and scientific claims. A language model that confidently provides a drug dosage that is incorrect, or cites a court case that doesn’t exist, can cause real harm if the output isn’t verified.
Every major language model hallucinates. The rate and type of hallucination vary by model, but none are hallucination-free. Treat factual claims from AI tools as starting points for verification, not as authoritative sources.
Deepfakes and Synthetic Media
Voice cloning and video generation have made it technically straightforward to create realistic audio and video of real people saying and doing things they never said or did. This capability (called a deepfake when used deceptively) has serious documented consequences: fraud using cloned executive voices to authorize financial transfers, political disinformation campaigns using synthetic video of candidates, and non-consensual intimate imagery generated from photographs. The same technology that makes voice synthesis useful for accessibility tools and content localization makes it dangerous when weaponized.
Bias and Representation
Generative AI models inherit the biases present in their training data. If the training data overrepresents certain demographics, perspectives, or cultural contexts, the model’s outputs will reflect those imbalances.
Language models trained primarily on English-language internet content will perform better in English than in other languages and will encode the cultural assumptions embedded in that content. Image generation models have documented tendencies to associate certain professions with particular races and genders. These are documented, measurable biases, not theoretical concerns.
Copyright and Intellectual Property

Generative AI systems are trained on copyrighted material (books, images, music, code) without explicit licensing from the creators. The legal framework for determining what this means for copyright holders is actively being litigated in multiple jurisdictions.
Several major lawsuits from publishers, record labels, news organizations, and artists were ongoing as of 2026. The outcomes will have significant implications for how generative AI companies train future models and what they owe to the creators whose work contributed to the training data.
Environmental Cost
Training large generative AI models consumes enormous amounts of energy. A single training run for a frontier model can consume megawatt-hours of electricity and generate significant CO₂ emissions.
Inference (generating outputs at scale for millions of users) is a continuous, ongoing energy cost. This environmental dimension of generative AI is underreported relative to its actual scale and merits consideration in any honest assessment of the technology’s impact.
How to Use Generative AI Responsibly and Effectively
Understanding the technology is half the picture. Using it well is the other half. Here’s how to use generative AI effectively and responsibly:
Verify Everything That Matters
Generative AI is a productivity tool, not an authority. For any factual claim you intend to act on, for instance, a medical decision, a legal interpretation, a financial judgment, or a news fact, verify against a primary source. The AI is a starting point, not a destination.
Be Specific in Your Prompts
The quality of a generative AI output is directly related to the quality of the prompt that produced it. Vague prompts produce vague outputs.
On the other hand, specific, detailed prompts (describing the context, format, audience, constraints, and goal) yield better, more meaningful results. The skill of prompting effectively is learnable and worth developing.
Treat AI Output As a First Draft, Not a Final One
The most effective users of generative AI use it to eliminate blank-page friction and get something on the page quickly, then edit, refine, and improve it. Using AI output as a direct final deliverable, without review or editing, is both the most common mistake and the one most likely to surface errors or expose the output as machine-generated.
Understand What the Tool Was Built For
Different AI tools are optimized for different tasks. A general-purpose LLM handles many tasks adequately.
A specialized tool, such as a coding assistant, a research tool with live web search, or a voice AI for customer service, handles its specific task better. Using the right tool for the right job is more effective than using a single general tool for everything.
Our best AI productivity apps guide covers how different tools serve different workflow needs.
Protect Your Data

Be thoughtful about what you enter into AI systems. Most consumer AI tools use interaction data to improve their models by default. Confidential business information, personal health data, financial details, and anything you wouldn’t want stored on a third-party server should either be kept out of AI prompts or used only with tools that have explicit data protection commitments relevant to your context.
Generative AI Across the Spectrum: Who Benefits Most
- Students and Learners: They gain on-demand access to patient information and detailed explanations at any hour. The value is most pronounced for learners who previously lacked access to tutoring or supplementary educational support, where generative AI genuinely democratizes access to learning.
- Writers, Marketers, and Content Creators: They use generative AI to reduce the time spent on first drafts, research, and ideation, freeing more time for editing, strategy, and the creative judgment that AI doesn’t replace. For coverage of how these tools are evolving, our AI Unboxed section tracks the most relevant releases.
- Developers and Technical Professionals: They use code generation tools to accelerate implementation, reduce context switching and access explanations for unfamiliar systems or languages. The time savings in professional software development are among the most measurable in any AI adoption study.
- Small Businesses and Individual Entrepreneurs: They benefit from access to capabilities that previously required specialist contractors, such as copywriting, graphic design, customer service, and data analysis, at a fraction of the historical cost.
- Healthcare, Scientific Research, and High-Stakes Professional Domains: They benefit most from AI assistance that augments expert judgment rather than replacing it, where a doctor using AI-assisted analysis still makes the clinical decision, or a lawyer using AI-assisted research still exercises professional judgment over the output.
Who Should Be Most Cautious
Anyone making consequential decisions in domains where accuracy is critical (medicine, law, finance, engineering and safety) should treat generative AI as a research aid rather than a decision-maker. The risk of hallucination is real, and the stakes in these domains make verification non-negotiable rather than optional.
FAQs
No. ChatGPT is one example of a generative AI application, specifically a conversational interface built on OpenAI’s GPT language models. Generative AI is the broader category encompassing all systems that generate content: language models, image generators, video generators, voice synthesis tools, and more. ChatGPT is to generative AI what Gmail is to email.
This is the hallucination problem, and it stems from how language models work. The model doesn’t retrieve stored facts; it predicts the most probable sequence of tokens given the context. When training data contains patterns that lead toward incorrect predictions, or when the model is asked about something outside its training distribution, the most probable output can be wrong. The model has no internal mechanism for distinguishing what it “knows” from what it’s inferring. That’s why verification of factual claims is essential.
It depends on the specific tool. Base language models like GPT-4o operate on training data with a knowledge cutoff; they don’t browse the live web by default. Tools with web search integration, such as Perplexity AI or ChatGPT with Browse enabled, combine a language model with live web retrieval to access up-to-date information. Always check whether the tool you’re using has a knowledge cutoff or live web access; it significantly affects how you should evaluate its outputs on time-sensitive topics.
Traditional AI systems are trained to classify, detect, or predict within defined categories: spam or not spam, fraud or legitimate, cat or dog. Generative AI is trained to learn the underlying distribution of data and produce new outputs that match that distribution. The key distinction: traditional AI analyzes, generative AI creates. Both have important roles; they’re optimized for different tasks.
The honest answer is: some roles will change significantly, some tasks across many roles will be automated, and new roles will emerge focused on managing and working effectively with AI systems. The historical pattern with major technological shifts is transformation rather than wholesale replacement; the nature of work changes faster than the total amount of work disappears. The roles most at risk are those involving high volumes of routine, predictable knowledge work. The roles most durable are those requiring complex judgment, interpersonal relationships, physical dexterity, and genuine creativity.
Yes. Many of the most capable tools offer genuinely functional free tiers. ChatGPT’s free tier provides access to GPT-4o Mini with usage limits. Perplexity AI’s free plan includes unlimited basic searches with citations. Gemini’s free tier can handle many everyday tasks. Image generation tools like Adobe Firefly offer free monthly credits. For a comprehensive look at which free tools deliver the most value, our best AI productivity apps guide covers the landscape across categories.
Conclusion

Generative AI is not a trend or a passing moment. It is a fundamental change in what software is capable of, and consequently, in how every industry that relies on content, code, language, or visual communication will function going forward. The technology works by learning patterns in human-created data at a massive scale and generating new outputs that match those patterns, using architectures such as transformers for language and diffusion models for images. It produces remarkable results, and it fails in documented, predictable ways.
Understanding both sides of that picture, the genuine capability and the genuine limitations, is what separates people who use generative AI effectively from people who are either dismissive of it or uncritically dependent on it. The tools are going to keep improving. The hallucination problem is being actively worked on. The legal and ethical frameworks are being developed in parallel with the technology itself. But the most important variable in how this technology affects your work and your life is how thoughtfully you engage with it, not just whether you use it at all.
Curious about what else the tech world has to offer? YourTechCompass.com is your guide to making smarter tech decisions, one honest review at a time.